Accessibility and multilingualism: an exploratory study on the machine translation of audio descriptions 1
Anna Matamala & Carla
Ortiz-Boix
Universidad Autónoma de Barcelona
This article presents the results of an exploratory study which assesses the machine translation of audio descriptions as offering a possible solution to increase accessibility in multilingual environments. Accessibility is understood to encompass two different categories: sensorial accessibility (in this specific case, for the blind and visually impaired, who cannot access the visual content of audiovisual productions), and linguistic accessibility (for those who want to access this content in their own language). The article presents some thoughts on translation as a means of promoting multilingualism, on the feasibility of translating audio descriptions, and on machine translation as applied to this audiovisual translation mode, before summarising the findings of the present study and, most importantly, opening up new potential avenues for research.
key words Audiovisual translation, accessibility, audio description, machine translation, multilingualism.
Accesibilidad y multilingüismo: un estudio exploratorio sobre la traducción automática de descripciones de audio
Este artículo presenta los resultados de un estudio exploratorio que evalúa la traducción automática de audiodescripciones como una posible solución para aumentar la accesibilidad en entornos multilingües. Se entiende que la accesibilidad abarca dos categorías diferentes: accesibilidad sensorial (en este caso específico, para los ciegos y discapacitados visuales, que no pueden acceder al contenido visual de las producciones audiovisuales) y accesibilidad lingüística (para aquellos que quieren acceder a este contenido en su propio idioma). El artículo presenta algunas reflexiones sobre la traducción como medio para promover el multilingüismo, sobre la viabilidad de traducir descripciones de audio y sobre la traducción automática tal y como se aplica a este tipo de traducción audiovisual, antes de sintetizar los hallazgos del presente estudio y, lo que es más importante, abrir la posibilidad de nuevas vías a la investigación.
palabras clave: Traducción audiovisual, accesibilidad, audiodescripción,
traducción automática, multilingüismo
Introduction
Accessibility to all aspects of life (including both to communication and information) is a human right recognised by the United Nations Convention on the Rights of Persons with Disabilities and fostered by national and international regulations: all audiences, regardless of their various capacities, should be able to access information and cultural products. E-Inclusion 2 and e-Accessibility 3 are part of the European agenda, with many EU actions promoting «access for all» via campaigns, policies and funded research projects. According to a communication on e-Accessibility 4, the European Commission «has the ambitious objective of achieving an ‘Information Society for All’, promoting an inclusive digital society that provides opportunities for all and minimises the risk of exclusion». However, the lack of accessible content is still a commonly reported problem affecting a significant percentage of the population. According to the World Report on Disability (World Health Organization, 2011), people with disabilities constitute about 15% of the European population, and given that disabilities are also very often associated with old age and that 30% of the European population is expected to be over 60 years of age by 2030, this is a matter of increasing concern. Article 7 of the European Audiovisual Media Service Directive establishes that «Member States shall encourage media service providers under their jurisdiction to ensure that their services are gradually made accessible to people with a visual or hearing disability», and various states have already implemented measures to this effect 5. For instance, the Spanish General Law on Audiovisual Media 6, passed in April 2010, states the need for public broadcasters to achieve the following percentages of accessible programmes by 2013, using the three key accessible modalities: to provide subtitling for the deaf and hard-of-hearing in 90% of their programmes, to broadcast 10 hours of programmes per week with accompanying sign language, and 10 hours with associated audio description (AD) for blind and visually impaired audiences.
Accessibility is therefore highly regarded and promoted by international institutions. Likewise, multilingualism is considered to be «an asset for Europe and a shared commitment», as pointed out in a communication issued by the European Commission in 2008, the aim of which was «to raise awareness of the value and opportunities of the EU’s linguistic diversity and encourage the removal of barriers to intercultural dialogue» 7. Section 7 of the aforementioned communication states that «[t]he media, new technologies and human and automatic translation services can bring the increasing variety of languages and cultures in the EU closer to citizens and provide the means to cross language barriers», recognising the great potential of the media for promoting intercultural dialogue. Linguistic accessibility in audiovisual media is often achieved by means of transfer modes such as dubbing, subtitling and voice-over, which bring audiovisual content closer to EU citizens by offering it in their native language.
Catering for sensorial and linguistic accessibility in multilingual environments is not easy in the current context of an economic crisis. Offering personalised and universally accessible materials using human resources is not always a priority in terms of the economic agenda, and only powerful stakeholders and widely-spoken languages might be able to achieve this. Our assumption is that technology can enhance both linguistic and sensorial accessibility by optimising current processes. However, further research into the specific application of the various available technologies (for instance speech recognition, machine translation and speech synthesis) and into the reception/acceptance of the final output should be conducted. With this dual objective in mind, two projects have been developed at Universitat Autònoma de Barcelona: Technologies for Accessibility (APOSTA2011-10) and ALST (Linguistic and Sensorial Accessibility, reference FFI2012-31024). The ultimate aim of these projects is to improve both linguistic and sensorial accessibility to audiovisual media, focusing on voice-over and audio description, and catering not only for audiences who do not understand the language (i.e. to promote linguistic accessibility) but also for those audiences who cannot access either the aural or visual content (i.e. to foster sensorial accessibility). Although research into these technologies in audiovisual translation (AVT) is already ongoing, the focus has thus far been on modes such as subtitling (see Aizawa et al, 1990; Popowich et al, 2000; O’Hagan, 2003; Melero et al, 2006; Volk, 2008; Volk et al, 2010; Sousa et al, 2011; Bywood et al, 2013; Alprandi et al, 2014) and not on AD.
The study presented in this article is part of these two broad projects but is far more limited in its scope: it describes the results of a small-scale exploratory piece of research which focuses on the machine translation (MT) of filmic audio descriptions from Catalan into Spanish. Audio description (AD) is an AVT mode consisting in inserting an oral explanation of the most relevant visuals (characters, settings, actions, etc.) in the silent gaps of audiovisual content such as films, theatre plays, operas and live events, amongst other productions, so that blind and visually impaired audiences (but also people who cannot momentarily access the visual content) can enjoy audiovisual products in a similar fashion to those who have full access to them.
Machine translation is seen in this article as a means of increasing accessibility in a multilingual country such as Spain, where many different languages are spoken, e.g. Spanish, Catalan, Basque or Galician. As indicated by Turell (2001), article number 3 of the Spanish Constitution (1978) recognises Spain’s national and linguistic plurality and grants official status not only to the Spanish language across the whole territory, but also to the other languages spoken in historic communities such as Basque, Catalan or Galician. Following Turell (2001:9), this view could even be expanded and multilingual Spain could be said to include not only these historically established communities, but also other smaller established linguistic communities (such as Aranese, Astur-Leonese or sign-language) and new migrant minorities (such as Chinese or Maghrebi, among others). The rationale behind our research is that in multilingual countries there is not only the need to provide accessible content for the blind and visually impaired (to facilitate sensorial accessibility) via audio descriptions, but there is also the need to provide this accessible content in the language of the audience (to allow for linguistic accessibility). Our hypothesis is that instead of creating audio descriptions ex novo for each different language, post-edited MT output could be efficiently used, particularly in closely related languages such as Spanish and Catalan, «recycling» efforts and reaching a wider audience. If successful, the scope of the project could be widened to include other language combinations, adopting a pan-European rather than a state-based approach.
The article begins with some general thoughts on the translation of audio descriptions. It must be stressed that, to the best of our knowledge, the few authors who deal with this topic focus only on human translation.
Considering the fact that the languages involved in our machine translation study are Spanish and Catalan, an overview is made concerning the current AD situation in Spain, and successful experiences in the field of machine translation in this language pair are described. Finally, methodological aspects as well as the results of our exploratory study are presented, and possible future research avenues are highlighted in the conclusions.
1. Translating Audio Description: The Way Forward?
Translating audio description is a discussion topic which has already been put forward by various researchers into audiovisual translation: Matamala (2006:297) considers that a feasible scenario would be that the professional in charge of translating a movie for dubbing could easily (and adequately) translate and adapt the whole AD for the film, previously provided in the film’s language. However, not all authors agree: Hyks (2005:8) considers that «translating and rewording can sometimes take as long if not longer than starting from scratch», whilst Vallverdú in Matamala and Orero (2009) believes that adaptation would be necessary, and transcribing and including time codes might also be time-consuming, making translation less time-consuming than the creation of the AD script from scratch. These opinions have thus far not been proven by experimental data, although some proposals to carry out such studies have been made (see the ongoing PhD research project by López Vera, 2006). Bourne and Jiménez (2007:176) state that as «a text for translation, AD represents a particular case with specific constraints, although similar to those in other types of audiovisual translation, such as dubbing. The translated text is primarily conditioned by the visual information offered on the screen, and by the amount of time/space available in between the dialogues to insert the description». They later point out that, although it is not a generalized practice, «translating ADs would seem to offer considerable advantage in terms of time and therefore cost in comparison with the present practice by which ADs are written from scratch by professional audio describers in different languages» (ibid: 176). The authors even compare the time devoted to preparing an AD script for a two-hour film according to ITC (International Test Commission) guidelines (up to 60 hours) to the time it would take to translate it (24 hours). Finally, Remael and Vercauteren (2010) go deeper into the topic and look at the specific challenges presented by translating existing AD scripts. Using two case studies, they highlight the two main types of challenges observed: firstly, the frequency and specific usage of certain grammatical forms, and secondly, the transfer of cultural references due to the possible distance between the original film, the AD used as a pivot translation and the target audience. Remael and Vercauteren (ibid.) conclude that human translation of AD scripts will undoubtedly increase in its share of the market due to its cost-effectiveness. They also point out that many audiovisual translators are not trained in the intersemiotic translation that an AD entails (in which images are translated into words), and hence departing from an existing AD (whereby content selection and word choice are already made) would speed up the overall process.
2. Audio Description in Spain
To the best of our knowledge, no ADs have been translated in the whole of Spain. As explained by Orero (2007), AD in Spanish has its origin on radio in the 1940s, at which time Gerardo Esteban provided a weekly description of a film. Together with the European project Audetel, this was the basis of the Spanish system Audesc (Hernández Bartolomé & Mendiluce Cabrera, 2004), which has been used by the Spanish association ONCE to produce audio described videos and DVDs exclusively in Spanish for its members, without catering for the linguistic variety of its regional agencies. Commercial ADs in Spanish are also available, although the number of these is lower. As far as television is concerned, according to CMT (2012), in 2012 AD in Spanish was provided by 45.8% of the national channels, with figures oscillating between 0.2 hours per week (Telecinco) and 25.1 hours per week (FDF), with a mean figure across the board of 1.85 hours per week. Theatre plays, operas, cinemas and museums also offer audio descriptions in Spanish, particularly in the major cities.
AD in Catalan is also widely available. This started in 1989, with the first film audio described in Catalan by the Catalan TV channel TV3 (Vila, 2006:128). In fact, this was the first audio described broadcast in a western country (Hernández Bartolomé & Mendiluce Cabrera, 2004:268), coming just after a description broadcast on the Japanese network NTV in 1983. Audio description continued in TV3 in the nineties with more TV series, and since 2006 a weekly film has been audio-described and broadcast every Friday. Children’s cartoons and soap operas have also been made accessible, making Catalan TV a leading broadcaster in Spain in terms of accessibility. According to CMT (2012), of the five regional channels owned by the Catalan TV corporation, TV3 provided 7 hours of AD per week; CS3+3XL offered 4 hours per week; and 33D broadcast 3 hours per week, whilst the news channel 3/24 and the sports channel ES3 provided no audio descriptions, probably due to the nature of their programmes. AD of live events, theatre plays, opera and art is also a very common practice in Catalan in Catalonia (Matamala, 2007), with active participation from both universities and associations.
In contrast, AD in Galician is almost non-existent. CMT (2012) indicates that in the study period no AD was provided by either of the two Galician TV channels. According to Rodríguez (2011:10), AD is almost limited to theatre plays by associations of blind and visually impaired people, with the first AD in Galician being the production of Lisístrata in 2003 by Valacar, a theatre group of the Spanish association ONCE. DVDs with AD in Galician are not available and only one audio described film has so far been shown in a movie theatre, as part of the project «Cine Accesible». As for AD in Basque, according to the report by CMT (2012), AD is non-existent on Basque television. As reported by Rodríguez (2011: 12), AD has been available in theatres in the Basque country since 2009 but these ADs are provided in Spanish, not in Basque. Basque has only so far been used to audio describe films in the Donostia International Film Festival in 2012. Finally, AD in the other native languages spoken in Spain is not available either.
All in all, AD broadcasts in Spain are largely provided in Spanish (country-wide) or in Catalan (largely in Catalonia), depending on the language of the audiovisual content. In other words, in a production dubbed from English into Catalan, AD is provided in Catalan, whilst in a Spanish theatre play in a Catalan theatre, AD is generally provided in Spanish, that is the language of the audiovisual content. It may well be that the same AD is produced ex novo for an American film depending on the dubbed version broadcast (in both Catalan or Spanish), whilst it may also be the case that exactly the same Italian opera shown both in Barcelona and in Madrid undergoes two different audio description processes. It can also be the case that a film dubbed into both Catalan and Spanish is only available to the blind and visually impaired in Spanish because the Spanish association ONCE is the only organisation to have made it accessible through its extensive and linguistically exclusive Audesc project, which only works with Spanish.
Taking into account these varied scenarios, we argue that it would make more sense to focus our efforts and provide users with the choice of language by translating previously created audio description scripts. Furthermore, the application of translation technologies should be researched as a way to speed up the process. This is the issue that this article will partially investigate. However, some successful experiences of machine translation in the two languages undergoing analysis will first be outlined in order to show that machine translation across this language pair is possible at various levels.
3. Machine Translation in Catalonia (ES>CAT, CAT>ES)
Machine translation between Catalan and Spanish is a reality. There are many free online engines that perform this task, such as the following (links last accessed in January 2013):
- Apertium (http://www.apertium.org/?id=translatetext)
- Google Translate (http://translate.google.cat/)
- Lucy Kwick Translator (http://www.lucysoftware.com/catala/traducci-automtica/lucy-lt-kwik-translator-/lucy-lt-quick-translator.html?parent=&subid=)
- OpenTrad (http://www.opentrad.com//index.php?idioma=ca)
- Instituto Cervantes (http://www.cervantes.es/lengua_y_ensenanza/tecnologia_espanol/informacion.htm)
- InterNostrum (http://www.internostrum.com/)
- ITranslate4EU (http://itranslate4.eu/)
- LexPress (http://www.standling.com/trad/)
- Softcatalà (http://www.softcatala.org/traductor)
- Salt (Valencian dialect) (http://www.cefe.gva.es/polin/val/salt/apolin_salt.htm)
- N- II (UPC): (http://www.n-ii.org/)
Machine translation in the Spanish<>Catalan language pair is being successfully undertaken in a variety of settings. Language services at Catalan universities use this means of translation: for instance, Universitat Oberta de Catalunya (UOC – the Open University of Catalonia) uses, among other software, the machine translation engine Apertium and the segment aligner SALI to optimize the translation process (Villarejo, Corral & Cullen, 2007). As for Universitat Autònoma de Barcelona (UAB), the Servei de Llengües (Language Service) uses a machine translation engine by Lucy Software that works in both translation directions.
Regarding the press, three newspapers use machine translation engines. El Periódico was the first newspaper to simultaneously publish both a Catalan and a Spanish edition. As stated by Fité (2006), language coordinator for the newspaper, machine translation has made it possible to produce two identical versions. It is important to highlight that there are not two different editions depending on the target language of the user, but that the contents are equivalent, and the language (be it Spanish or Catalan) is the only thing that varies. News is produced in Spanish and is machine translated into Catalan in just a few seconds, with a subsequent human post-editing stage being conducted by expert Catalan language editors (Fité, 2006). A similar approach has been adopted by La Vanguardia, one of the most widely read newspapers in Catalonia, and by Segre, a local newspaper edited in Lleida.
The above examples show that machine translation is used not only in technical contexts, with very specific vocabulary domains and text structures, but can also be feasibly used in more general contexts such as the press, at least in this combination of closely related languages.
4. Translating AD from Catalan into Spanish: Methodological Aspects
The research presented in this section explored the feasibility of applying machine translation to translate a small corpus of Catalan AD into Spanish. The corpus selected comprises the following: the Catalan AD of the first chapter of the series Gran Nord (Font, 2012), which lasts 55:35 minutes, and 30 minutes of the Catalan AD of the film Bruc (Benmayor, 2010). The later selection comprises a sample of the film: the first ten minutes, the last ten minutes, and ten minutes selected from the middle of the film. The final total for translation was almost 90 minutes of audio described film, containing a total of 4,384 words organised in 442 sentences. Written AD scripts were provided by Catalan Television, 8 and images were recorded from the television when broadcast.
Two different engines were selected to carry out the experiment. The engines selected were Apertium and Google Translate. Apertium is an open-source and rule-based machine translation (RBMT) engine created by Universitat d’Alacant and Prompsit (http://www.apertium.org/), and is used by Universitat Oberta de Catalunya (see http://apertium.uoc.edu/), as previously noted. It includes Spanish, English, French and Catalan. According to Forcada et al (2011), it is particularly designed for closely related-language pairs (such as the languages researched for this paper), although it also deals with more divergent pairs (such as English<>Catalan). Google Translate is a statistical MT (SMT) engine created by Google. This engine currently works with 65 different languages including Spanish and Catalan, and intends to make information universally accessible and useful regardless of the source and target languages (Google Translate, 2013). Both engines were selected not only because they are openly available resources but also because they represent two different types of machine translation engine.
It was decided to use a statistical MT engine without specific training given that ADs scripts are not currently translated and a bilingual corpus was not readily available. Moreover, our interest lay in observing the results that openly available resources would yield. This is because we envisage this working model as offering a solution not only in professional contexts but also, and perhaps most importantly, in amateur environments in which people voluntarily cooperate to work towards producing a greater number of accessible products.
Concerning the evaluation of the results, it was decided to carry out a human subjective evaluation based on error categorization, carried out by one assessor. Taking as a point of departure the proposals of both Font-Llitjós et al (2005) and Koponen (2012), the following categorization was established for the purposes of the present study:
- Missing Word: refers to words present in the source text which have been eliminated in the translated text.
- Untranslated Word: includes words in the source language that appear in the target text because they have not been recognised by the engine and have not been translated.
- Extra Word: words that are not in the source text but which are included in the translated text.
- Wrong Word Order: the word order of the translated sentence is not the appropriate one according to the syntax of the target language.
- Incorrect Word: refers to words that have been incorrectly translated.
- Mistranslated Word: when direct equivalents to the source word are used but are not the best translation option for a specific context.
- Wrong Agreement: as the label indicates, in these cases the agreement of the words in the target text is incorrect (gender/number/etc.).
This system of categorization was used to quantify and classify the number of errors produced by both translation engines. Although additional objective metrics could have been implemented, the aim was to carry out an exploratory piece of research, and hence a human-based approach was considered to be sufficient at this stage of our enquiry.
5. Results and Discussion
The aim of this section is to provide a comparison of the results of both engines, and to classify the main mistakes that were to be found in the translation of our corpus, along with presenting some illustrative examples. As previously indicated, the corpus to be translated was made up of 4,384 words, distributed across 442 sentences. The machine-translated output contained the same number of segments but the number of words differed: 4,566 words for the translation by Google Translate and 4,599 for that of Apertium.
Taking sentences as a unit, it was observed that Google Translate generated 171 sentences out of 442 which included at least one mistake (an error rate of 42.22%), whilst 271 sentences could be kept without any need for full post-editing. The figures for Apertium were 234 sentences containing mistakes (an error rate of 57.78%) and 208 acceptable sentences, as shown in Figure 1.
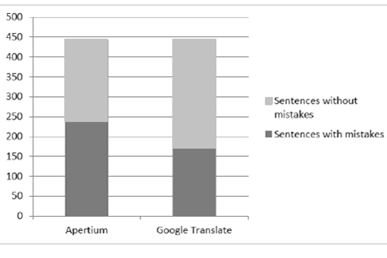
Figure 1: Sentences with/without mistakes
Concerning the number of errors, the data show that Google Translate produced 254 mistakes, which corresponds to 5.56% of the words, whilst Apertium’s output contains 506 errors - 11% of the words. Summing up both figures, the results show a total of 760 errors (an average error rate of 8% of the translated corpus).
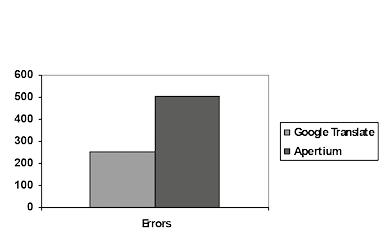
Figure 2: Number of errors per MT engine
All in all, the data prove that Apertium has a higher error rate per word and per sentence than Google Translate for the selected corpus. It remains to be seen whether specific training of an SMT engine with monolingual or bilingual corpora of AD (not currently available) or the addition of specific linguistic rules could improve these results.
Regarding the categorisation of errors found in our corpus, the following (with the exception of the «extra word» category of which there were no instances) was found in decreasing order of frequency. It must be highlighted that errors may have a different impact on the final text (for instance, some may weight more, as they affect the accuracy of the final text, whilst others may not), but this was not assessed in our analysis.
Wrong Word Order
Our analysis found 304 mistakes of this type (39.8% of the total number of mistakes), with differing values between Apertium (175) and Google Translate (129). A recurrent error found in our corpus is shown below:
(1) Original: Per darrere se li acosta l’Ermengol.
Machine output: Por detrás se le acerca el Ermengol
Source: Gran Nord.
Engine: Google Translate.
Remarks: The meaning in both sentences is exactly the same (Ermengol approaches her from behind). However, Catalan uses an article before proper names («l’Ermengol») whilst Spanish does not («Ermengol»), a feature that is not correctly translated by either of the two engines used. The mistake is highlighted in italics above.
Wrong Agreement
Concerning wrong agreement, the results show 50 mistakes with the output from Google Translate and 123 when using Apertium. Some examples are included below in order to illustrate typical errors in this category, with the specific error being highlighted in italics.
(2) Original: S’acosta a una prestatgeria plena de copes, trofeus i medalles.
Machine output: Se acerca en una estantería llena de copas, trofeos y medallas.
Source: Gran Nord.
Engine: Google Translate.
Remarks: Although accuracy is not compromised (She approaches a shelf full of cups, trophies and medals), a preposition is incorrectly used: instead of «en» it should be «a». Hence, the grammatically correct translation would be «Se acerca a una estantería llena de copas, trofeos y medallas».
(3) Original: L’Anna mou lentament el cap a banda i banda, somrient; tots els de Nord i en Pep l’observen fent un cercle de caps damunt seu.
Machine output: El Anna mueve lentamente el hacia banda y banda, sonriente; todos los de Norte y en Pep lo observan haciendo un círculo de jefas encima suyo.
Source: Gran Nord.
Engine: Apertium.
Remarks: Although the translation presents various problems such as the inclusion of an article before proper nouns («L’Anna» should be «Anna» in Spanish, and not «El Anna», for instance) and some mistranslated words («el cap» should be «la cabeza» in Spanish and not «el hacia» in the first part of the sentence, whereas «caps» should be translated as «cabezas» and not «jefas» in the second part), the incorrect agreement is to be found in the masculine pronoun «lo», highlighted in italics. This pronoun refers to a feminine word meaning the feminine pronoun «la» should have been used («la observan»).
(4) Original: Amb els bastons encesos, a manera de torxes, entren en una cova de passadissos estrets.
Machine output: Con las bastones encendidos, a modo de antorchas, entran en una cueva de pasillos estrechos.
Source: Bruc.
Engine: Google Translate.
Remarks: The meaning is maintained in this sentence (With burning sticks, like torches, they enter into a cave with narrow corridors). However, «bastones» is masculine and the masculine article should therefore have been used. In other words, instead of «las bastones», the translation should read «los bastones».
Incorrect Words
The inclusion of incorrect words is to be found in 42 instances when using Google Translate, whilst Apertium generates 111 mistakes of this type, as shown in the examples below:
(5) Original: Els veu a passar tots, equipats per anar a caçar, i els torna el salut, alçant dos dits enlaire amb els altres tres recollits.
Machine output: Los ve a pasar todos, equipados para ir a cazar, y los vuelve el salud, levantando dos dedos en alto con los otros tres recogidos
Source: Gran Nord.
Engine: Apertium.
Remarks: the original sentence means He sees them all, ready to hunt, and returns their greeting by lifting his index and middle figure whilst keeping the rest closed. Apart from other problems, which do not belong to this category, the incorrect word found in this sentence is «salud» (literally, «health»), which is a mistranslation of the Catalan «salut», meaning «greeting», in this context, as itshould be replaced by «saludo».
(6) Original: Els ulls del Bruc ressalten en la foscor, arran de paret.
Machine output: Los ojos del Bruc resaltan en la oscuridad, a raíz de pared
Source: Bruc
Engine: Google Translate.
Remarks: Although the first part of the sentence maintains the meaning (Bruc’s eyes shine in the dark), the second part, meaning «next to the wall», is incorrect because «arran de» (literally, «next to») has been translated as «a raíz de» (literally, «because of»), which will result in an accuracy problem.
Mistranslated Words
In this category, 22 mistakes are to be found when using Google Translate, and 47 mistakes when using Apertium. One example to illustrate typical mistakes is presented below, depicting words that are not the best option for the selected context although comprehension is still possible.
(7) Original: En Maraval cavalca davant d’en De la Mata, que camina amb la Glòria, lligada.
Machine output: En Maraval cabalga ante en De Mata, que anda con la Gloria, ligada.
Source: Bruc.
Engine: Apertium.
Remarks: The machine output presents one recurrent error (including an article before a proper noun in Spanish). However, the mistranslated word is «lligada», which is rendered in the Spanish as «ligada». Although the meaning of the original is conveyed in the translation, there is a more frequent adjective that would more naturally be used in this context («atada»). In spite of this fact, the sense of this AD excerpt is still transferred («Maraval rides in front of De la Mata, who walks with Glòria, tied up»).
Untranslated Words
Google Translate does not translate nine words of the corpus, whilst the number of mistakes of this type increases to 49 when using Apertium. Two examples of this type of error are provided below.
(8) Original: A fora, un genet amb turbant blau i un sabre a l’esquena espera en el corriol.
Machine output: Afuera, un jinete con turbante azul y un sable a las espaldas espera en el corriol.
Source: Bruc.
Engine: Apertium.
Remarks: In this sentence (meaning Outside, a horseman in a blue turban and a sabre on his back waits in a small trail), the word «corriol» (meaning a «small trail») is kept in Catalan in the Spanish machine-translated version, and is thereby an example of a non-translated word which compromises accuracy.
(9) Original: L’Anna es treu la identificació que porta penjada del coll, agafa un portafolis per la finestra d’un cotxe i pren notes.
Machine output: El Anna se saca la identificación que trae colgada del cuello, coge un portafolis por la ventana de un coche y toma notas.
Source: Gran Nord.
Engine: Apertium.
Remarks: The meaning of the sentence is comprehensible (Anna takes out the ID hanging on her neck, takes a folder through the car’s windows and takes notes). However, quite apart from other errors in the sentence (which fall into other categories), there is a word that is not translated at all in the Spanish version: «portafolis»).
Missing Words
Finally, the number of instances of this type of mistake is very low for both engines, with 2 instances using Google Translate and 5 for Apertium. One example is reproduced below:
(10) Original: Els veu passar a tots, equipats per anar a caçar.
Machine output: Los ve pasar todos, equipados para ir a cazar.
Source: Gran Nord.
Engine: Google Transle.
Remarks: Although accuracy has not been compromised (He sees them all, ready to hunt), there is a word missing in the Spanish version, namely the preposition «a» before the object. «Los ve pasar todos» should read «Los ve pasar a todos».
As a means of summarising, Table 1 presents the number of mistakes per category, differentiating between the two translation engines. The rather low number of errors produced by Google Translate seem to indicate that using an SMT to translate the AD could help increase its presence in both languages if the output is post-edited afterwards.
|
Table 1 |
||
|
Category |
Google Translate |
Apertium |
|
Extra Word |
0 |
0 |
|
Missing Word |
2 |
5 |
|
Untranslated Word |
9 |
49 |
|
Mistranslated Word |
22 |
47 |
|
Incorrect Word |
42 |
111 |
|
Wrong Agreement |
50 |
123 |
|
Wrong Word Order |
129 |
175 |
|
Total |
254 |
510 |
6. Conclusions
This article has presented a piece of exploratory research that proposes a new application of machine translation for the translation of audio descriptions. The cost of the audio description process makes it difficult to increase the presence of audio description beyond the figures established by law. As a result, new solutions have to be found, ranging from the implementation of technological solutions (machine translation, and text-to-speech) to the adoption of crowd-sourcing approaches. This article offers a solution (which is still undergoing research) that could help cater for the needs of visually impaired people in multilingual countries, such as Spain, by offering them the option of an AD language choice. This corresponds to our view that in multilingual countries, accessibility should be offered not only in one language (usually the dominant one) but would ideally be available in the many and varied languages of the country’s citizens.
The data obtained in this study show that, taking words as a unit, 8% of the automatically translated corpus contains errors. On the other hand, if taking sentences as a reference, mistakes are to be found in around half of the corpus (with percentages of 42.22% for Google Translate and 57.78% when using Apertium). The possibility of improving these figures with specific training in the case of SMT on the one hand, and on the other the effort needed to post-edit the raw machine translation output and raise its quality to the required standards, are undoubtedly two key issues requiring further investigation. Measuring the post-editing effort as opposed to a process involving both human AD creation and human AD translation is an aspect worth analysing at various levels, and we hope to shed light on this in the near future.
All in all, this article advocates for wider accessibility in multilingual societies and assesses the implementation of a specific technology (that of machine translation), which would ideally increase the presence of accessible audiovisual content in the language(s) of the audience.
Recibido en julio de 2014
Aceptado en marzo de 2015
Versión final de septiembre de 2015
References
Aizawa, T. & Ehara, T. & Uratani, N. & Tanaka, H. & Kato, N. & Nakase, S. & Aruga, N & Matsuda, T. (1990). «A machine translation system for foreign news in satellite broadcasting». Proceedings of the 13th conference on computational linguistics (Helsinki, Finland). 308-310.
Aliprandi, C., Gallucci, I., Piccinini, N., Raffaelli, M., del Pozo, A., Álvarez, A., Cassaca, R., Neto, J., Mendes, C., Viveiros, M. (2014) «Assisted Subtitling: a new opportunity for Access Services», the International Broadcasting Conference 2014 (IBC2014), September 10-15 2014, Amsterdam, The Netherlands.
Benecke, B. & Dosch, E. (2004). Wenn aus Bildern Worte warden. Munich: Bayerischer Rundfunk.
Bourne, J. & Jiménez, C. (2007). «From the visual to the verbal in two languages: a contrastive analysis of the audio description of The Hours in English and Spanish». In: Díaz-Cintas, J. & Orero, P. & Remael, A. (Eds.), Media for All. Subtitling for the Deaf, Audio Description, and Sign Languages. Amsterdam: Rodopi. 175-188.
Braun, S. (2008). «Audiodescription research: state of the art and beyond». Translation Studies in the New Millennium. Vol. 6. 14-30.
Bywood, L; Volk, M; Fishel, M; Georgakopoulou, P. (2013). «Parallel subtitle corpora and their applications in machine translation and translatology». Perspectives: Studies in Translatology, 21(4):595-610.
CMT (Comisión del Mercado de las Telecomunicaciones). (2011). Indicadores de accesibilidad en televisión. From http://informecmt.cmt.es/docs/Anexos/Indicadores%20accesibilidad%20CMT%202011.pdf (last accessed 15th February 2013).
Delabastita, D. & Grutman, R. (2005). (Eds.) «Fictionalising translation and multilingualism». In: Special issue of Linguistica Antverpiensia New Series. Vol. 4/2005.
Fité, R. (2006). «Cas d’integració de la TA: el Periódico». Tradumàtica, 4. From http://ddd.uab.cat/pub/tradumatica/15787559n4a9.pdf (last accessed 8th April 2013).
Font-Llitjós, A. & Carbonell, J. G. & Lavie, A. (2005). «A Framework for Interactive and Automatic Refinement of Transfer-based Machine Translation». Computer Science Department. Paper 286.
Forcada, M. L. & Ginestí-Rosell, M. & Nordfalk, J. & O’Regan, J. & Ortiz-Rojas, S. & Pérez-Ortiz, J. A. & Sánchez-Martínez, F. & Ramírez-Sánchez, G. & & Tyers, F. M. (2011). «Apertium: a free/open-source platform for rule-based machine translation». Machine Translation. Vol. 25(2). 127-144.
Google Translate. (2013). Inside Google Translate. From http://translate.google.es/about/ (last accessed 15th April 2013).
Hernández-Bartolomé, A. & Mendiluce-Cabrera, G. (2004) «Audesc: translating images into words for Spanish visually impaired people». Meta. Vol. 49(2). 264-277.
Hyks, V. (2005). «Audio Description and Translation. Two related but different skills». Translating Today. Vol. 4.
Koponen, M. (2012). «Comparing human perceptions of post-editing effort with post-editing operations». Proceedings of the 7th Workshop on Statistical Machine Translation. 181-190. «Montréal: Association of Computationtal Linguistics».
López Vera, F. (2006). Traducir audiodescripciones. ¿Una necesidad inminente?. Congreso Amadis 2006. From http://www.cesya.es/estaticas/congreso/Ponencias/Resumenes/05.pdf (last accessed 15th October 2012).
Matamala, A. (2006). «La accesibilidad en los medios: aspectos lingüísticos y retos de formación». In: Pérez-Amat, R & Pérez-Ugena, Á. (Eds.), Sociedad, integración y televisión en España. Madrid: Laberinto. 293- 306.
Matamala, A. & Orero, P. (2009). «L’accessibilitat a Televisió de Catalunya: parlem amb Rosa Vallverdú, directora del departament de Subtitulació de TVC». Quaderns. Vol. 16. 301-312.
Melero, M. & Oliver, A. & Badia, T. (2006). Automatic Multilingual Subtitling in the E-Title project. From http://www.mt-archive.info/Aslib-2006-Melero.pdf (last accessed 11th November 2012).
Meylaerts, R. (2006). «Heterolingualism in/and Translation. How legitimate are the Others and his/her language? An introduction». Target. International Journal of Translation Studies. Vol. 18(1). 1-15.
— (2012). «Multilingualism and the limits of translation». Keynote lecture. The Translation and Reception of Multilingual Films Conference. (Montpellier, 15-16 June 2013).
O’Hagan, M. (2003) «Can language technology respond to the subtitler’s dilemma? A preliminary study». Translating and the Computer, 25. From www.mt-archive.info/Aslib-2003-OHagan.pdf (last accessed 11th November 2012).
Orero, P. (2007). «Sampling audio description in Europe». In: Díaz-Cintas, J & Orero, P. & Remael, A. (Eds.) Media for All. Subtitling for the Deaf, Audio Description, and Sign Languages. Amsterdam: Rodopi. 111-126.
Popowich, F. & McFetridge, P. & Turcato, D. & Toole, J. (2000). «Machine translation of closed captions». Machine translation. Vol. 15(4). 311-341.
Puigdomènech, L. & Matamala, A. & Orero, P. (2010). «Audio description of Films: State of the Art and a Protocol Proposal». In: Bogucki, Lukasz & Kredens, Krysztof (Eds.), Perspectives on Audiovisual Translation. Frankfurt: Peter Lang. 27-44.
Remael, A. & Vercauteren, G. (2010). «The translation of recorded audiodescription from English into Dutch». Perspectives. Studies in Translatology. Vol.18(3). 155-171.
Rodríguez, C. (2011). La audiodescripción en Galicia: panorama actual a través del cortometraje audiodescrito. Illa Pedra (Adriana Páramo 2010). Unpublished MA dissertation. European MA in Audiovisual Translation, Universitat Autònoma de Barcelona.
Sousa, L. & Azis, W. & Specia, L. (2011). Assessing the post-editing effort for automatic and semi-automatic translations of DVD subtitles. From http://clg.wlv.ac.uk/papers/ranlp-2011_sousa.pdf (last accessed 25th October 2012).
Turell, M. T. (Ed.). (2001). Multilingualism in Spain. Clevedon: Multilingual Matters.
Vila, P. (2006). Accesibilidad en Televisión de Cataluña. In: Pérez-Ugena, A & Utray, F. (coord.) TV Digital e Integración. ¿TV para todos? Madrid: Universidad Rey Juan Carlos & Dykinson. 127-130.
Villarejo, Ll. & Corral, A. & Cullen, D. (2007). «La integració de les tecnologies de la llengua en el flux de treball del Servei Lingüístic de la UOC». Llengua i ús. Revista técnica de Política Lingüística. Vol.46. 81-89.
Volk, M. (2008). «The Automatic Translation of Film Subtitles. A Machine Translation Success Story? » In: Nivre, J. & Dahllöf, M. & Megyesi, B. (Eds.): Resourceful Language Technology: Festschrift in Honor of Anna Sågvall Hein. Vol. 23(2). 113-125.
Volk, M. & Sennrich, R. & Harmeier, C. & Tidström, F. (2010). «Machine Translation of TV subtitles for large scale production». In: Vensislaz Zhechev (Ed.), Proceedings of the Second Join EM + ICNGL Workshop. 53-62.
Walsh Hokenson, J. & Munson, M. (2007). The Bilingual Text. History and Theory of Literary Self-Translation. Manchester: St. Jerome.
2 http://ec.europa.eu/digital-agenda/life-and-work (last accessed 15th July 2015).
3 http://ec.europa.eu/digital-agenda/en/news/study-assessing-and-promoting-e-accessibility (last accessed 15th July 2015).
4 http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52005DC0425&from=EN (last accessed 15th July 2015).
5 http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32010L0013&from=EN (last accessed 15th July 2015).
6 http://www.boe.es/boe/dias/2010/04/01/pdfs/BOE-A-2010-5292.pdf (last accessed 15th July 2015).
7 http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52008DC0566&from=EN (last accessed 15th July 2015).
8 We would like to thank Rosa Vallverdú for her help in providing us with the written scripts.