:: TRANS 27. MISCELÁNEA. Audiovisual. Págs. 151-171 ::
Translation of Interjections and Subtitling: A Study Based on the BETA Corpus of TV Series and Film Subtitles
-------------------------------------
Francisco Javier Díaz-Pérez
Universidad de Jaén
ORCID: 0000-0001-6772-0852
-------------------------------------
Interjections, often considered minor and peripheral linguistic elements, have been disregarded in both linguistic and translation-studies research. The main aim of this paper, in this sense, is to analyse the translation of three primary and three secondary interjections in a parallel English-Spanish corpus of subtitles. More specifically, the interjections under study were ah, wow, ugh, God, damn, and shit, and the corpus used was the BETA corpus. Four main translation solutions have been identified: literal translation, translation by an interjection with a different form, translation by a textual fragment which contains no interjection, and omission. The results of the study indicate that the most frequent translation solution in the whole corpus has been omission, followed by the translation by a different interjection. In a more fine-grained analysis, the two variables analysed, namely type of interjection and specific interjection, have been found to condition the choice of translation solution.
key words: audiovisual translation, subtitling, interjections, corpus, English into Spanish, translation solutions.
Traducción de interjecciones y subtitulación: un estudio basado en el corpus BETA de subtítulos de series de televisión y películas.
Las interjecciones, con frecuencia consideradas elementos lingüísticos periféricos y menores, no han recibido mucha atención en la investigación en el ámbito de la lingüística y de los estudios de traducción. El objetivo principal de este artículo es analizar la traducción de tres interjecciones primarias y tres secundarias en un corpus inglés-español de subtítulos. Concretamente, se analizaron las interjecciones ah, wow, ugh, God, damn y shit en el corpus BETA. Se identificaron cuatro soluciones de traducción: la traducción literal, la traducción mediante una interjección con una forma diferente, la traducción mediante un fragmento textual sin ninguna interjección y la omisión. Los resultados del estudio indican que la solución de traducción más frecuente fue la omisión, seguida de la traducción por una interjección diferente. En un análisis más detallado, se demostró que las dos variables analizadas, tipo de interjección e interjección específica, condicionaron la elección de la solución de traducción.
PALABRAS CLAVE: traducción audiovisual, subtitulación, interjecciones, corpus, inglés a español.
-------------------------------------
recibido en enero de 2023 aceptado en junio de 2023
-------------------------------------
1. Introduction
Interjections are very closely related to oral language, and, although sometimes they have been considered as almost non-linguistic elements (Ameka, 1992; Cuenca, 2000, 2002, 2006), the fact is that their nature as orality markers makes them prone to appear profusely in the dialogues of films and TV series. Their translation constitutes a thorny issue, as more often than not there is not a clear correspondence across languages. The fact that their meaning, rather than referential, is pragmatic and context-dependent adds to the complexity of interjection translation.
The main objective of the present paper consists in analysing the translation of six interjections in the BETA corpus, a bilingual English-Spanish corpus of film and TV series subtitles. In addition, two variables—type of interjection and specific interjection within each of the two types—were analysed to determine whether they had any effect on the choice of translation solution. The six interjections under analysis were ah, wow, ugh, God, damn, and shit. As one of the aims of the study was to analyse the effect of the type of interjection on the choice of translation solution, it was decided to select three primary and three secondary interjections. Moreover, the six interjections are frequently used in English, which is reflected in the number of tokens extracted from the corpus. All in all, 991 tokens of the six before-mentioned interjections, together with their textual counterparts in the Spanish subtitles, have been retrieved from the corpus and analysed.
The scarcity of studies focusing on the translation of interjections in general, and in particular from English into Spanish, justifies the objective of this paper. In fact, to the best of my knowledge only three studies dealing with the translation of English interjections into Spanish have been published within the modality of audiovisual translation, namely Maria Josep Cuenca (2002), Cuenca (2006), and Pablo Zamora and Arianna Alessandro (2016). The first two studies were centred on the Spanish and Catalan dubbed versions of Four Weddings and a Funeral, whereas the third one focused on the Spanish dubbed versions of two Italian films: Manual d’amore and Ex.
The next section focuses on the definition and different classifications of interjections, as well as on their translation, in section 3 the main methodological aspects of the present study are dealt with, section 4 presents and discusses the results reached in this investigation, and finally, section 5 offers some concluding remarks.
2. INTERJECTIONS: DEFINITION, CLASSIFICATION AND TRANSLATION
2.1. Definition
Interjections constitute a controversial and heterogeneous grammatical category, as has been highlighted more than once (Cuenca, 2000, 2006; Meinard, 2015; Qin & Valdeón, 2019; Jing, 2021). Their peculiarity has led some linguists to consider that interjections resemble non-linguistic elements, such as gestures, and in that sense, they are sometimes described as peripheral to language (Cuenca, 2006). Probably because of that, they have received much less attention than other word classes, in spite of the fact that they play a fundamental role in communication, as signalled by Mohammad Ahmad Thawabteh (2010).
As stated by Anna Matamala (2009), there is not a clearly established definition of interjection. Thus, different theoretical approaches concentrate on specific subcategories of interjections and analyse particular characteristics from different perspectives. In spite of the heterogeneity of interjections and the discrepan cies across linguists with regard to their nature, there is a high consensus, however, with respect to some of their features, such as the following ones:
- Interjections are morphologically inva riable, that is to say, they cannot normally take inflectional or derivational morphemes. (Ameka, 1992; Cuenca, 2000; Meinard, 2015; Matamala, 2009)
- They are syntactically independent, which implies that they can be used on their own as utterances. (Bloomfield, 1933; Wierzbicka, 1992; Cuenca, 2000; Matamala, 2009; Meinard, 2015; Jing, 2021)
- Derived from their utterance-like behaviour, interjections are complete both from an intonational and semantic perspective. (Cuenca, 2000; Matamala, 2009)
- They can encode subjective values or prag matic meanings, such as surprise, excite ment, pain, etc. (Ameka, 1992; Wierzbicka, 1992; Cuenca, 2000; Matamala, 2009)
- They are highly context-dependent, or, in other words, their interpretation will be determined by the context in which they are produced. (Ameka, 1992; Matamala, 2009; Jing, 2021)
2.2. Classification
One of the basic classifications of interjections, firstly established by Bloomfield (1933), is that which divides them into primary and secondary. As defined by Cuenca (2006, p. 21), “[p]rimary interjections are simple vocal units, sometimes very close to nonverbal devices.” Primary interjections, which are not used otherwise, may be illustrated by words such as oh, wow, gee, ouch, ah, and ugh, among others.
Secondary interjections, in turn, are described as “words or phrases which have undergone a semantic change by pragmaticization of meaning and syntactic reanalysis, in other words they are grammaticalized elements.” (Cuenca, 2006, p. 21). Examples of secondary interjections are words like God, damn, hell, or phrases like My Goodness, Thank God, Dear me, to mention just a few.
According to the function they serve, inter jections may be classified under three categories, namely expressive, conative, and phatic. Expressive interjections are related to the addresser’s mental state and, in Felix Ameka’s typology (1992, p. 113), may be divided into two subgroups: emotive and cognitive. Emotive interjections convey speakers’ inner emotions, whereas cognitive interjections are related to the speaker’s thoughts and state of knowledge at the time of the utterance. Wow, ouch or ugh may be included among the former, and aha is an example of the latter. Conative interjections, for their part, are addressed to a hearer, from whom either attention or a given action or response is demanded. Thus, sh or hush, for instance, are used to request for silence. Finally, the function of phatic interjections, such as mhm or uh-huh, is to establish and maintain communication with an addressee.
Similarly, Anna Wierzbicka’s (1992) classi-fication distinguishes three types of interjections: emotive, volitive and cognitive, which implies that Ameka’s (1992) expressive category has been divided into two independent categories in Wierzbicka’s (1992) typology. Ameka’s conative interjections, in turn, roughly correspond to Wierzbicka’s (1992) volitive interjections. Phatic interjections, however, have no correspondence in Wierzbicka’s proposal.
Although some classifications (Bally, 1950; Barbéris, 1992; Rusu, 2015; Cuenca, 2000; Swiatkowska, 006; Vassileva, 2007) and many dictionaries and grammars include onomatopoeias as a type of interjection 1, Ge orges Kleiber (2006) and Maruszka Eve Marie Meinard (2015) defend that onomatopoeias should be distinguished from interjections on both semantic and grammatical grounds. Moreover, Meinard (2015) also points out that interjections do not constitute a grammatical category, since:
- They are sentence substitutes.
- They contain a predicative relation in their semantic core.
- The criteria determining a category cannot be applied to interjections (they are semantically bleached, syntactically isolated, morphologically anomalous and cannot take inflexions). The only defining criterion for secondary interjections is a cross-category one: a semantic bleach and a syntactical shift occur during their “conversion” (Meinard, 2015, p. 167).
2.3. On the translation of interjections
Huang Qin and Roberto A. Valdeón (2019) point out that in spite of the important pragmatic functions of interjections and expletives in conversation, their translation did not receive much attention in academic research. As put forward by Cuenca (2006, p. 21), “[t]ranslating interjections is not a matter of word translation. It implies translating discourse meanings which are language-specific and culturally bound.” Among the few studies on the translation of interjections, a first group deals with the two main modalities of audiovisual translation: dubbing (Cuenca, 2002, 2006; Matamala, 2007, 2009) and subtitling (Thawabteh, 2010; Xian, 2015; Jing & White, 2016), whereas a second group is centred on drama translation (Farhoudi, 2012; Shahraki, Karimnia & Mashhaddy, 2012; Drzazga, 2019).
Cuenca (2002) and Cuenca (2006) analyse interjections in the film Four Weddings and a Funeral and their translation into both Spanish and Catalan for their dubbed versions. Cuenca (2002)—a study on the translation of both primary and secondary interjections—concludes that interjection translation depends not only on the translator and dubbing specific requirements, but also on the type of interjection. In this sense, the tendency for primary interjections is to omit them in the target text (TT), whereas secondary interjections are mainly translated by means of an interjection with a different form and the same meaning. The results of Cuenca (2006) indicate that literal translation, which often leads to pragmatic interference and error, is much more frequent in Spanish than in Catalan. Cuenca says, in this regard, that “[a]ssuming that interjections are idiomatic units, dynamic (non-literal) translation is often the best option in a high proportion of cases” (Cuenca, 2006, p. 32). Other studies, such as Matamala (2004, 2007) and Carmen Valero (2001) support the same hypothesis. Thus, Matamala (2007), a study also centred on dubbing and which analyses the translation of the interjection oh into Catalan, has proved that, in spite of the existence of a homograph interjection in Catalan, the most frequently used translation solutions were omission and translation by an interjection with a different form. It is then concluded that even in those cases in which source language (SL) and target language (TL) share the same written form, their usages may be different, which should be taken into account by translators (Matamala 2007). María Jesús Rodríguez Medina (2009), a study on the translation of interjections in the British novel Jemima B., also alerts against the pragmatic calque of this interjection. Elsewhere, Matamala (2009) compared inter-jections in three different corpora: a corpus of sitcoms dubbed into Catalan, another corpus of sitcoms with Catalan original soundtrack, and a third corpus of spontaneous oral Catalan language. It was found that, in comparison with dubbed-into-Catalan sitcoms, the number and proportion of interjections in sitcoms which were originally shot in Catalan was much closer to what was registered in spontaneous speech. The results of Zamora and Alessandro (2016) do not corroborate this finding, as the number of primary interjections in films which were dubbed into Spanish was higher than that of films originally shot in Spanish. In addition, it was found that the translation techniques used to render interjections were literal translation, substitution with another primary interjection, and omission, in this order.
Juan Gómez Capuz (2001), a study on pragmatic interference from English into Spanish, contains a section on the translation of interjections for dubbing. In the dubbing corpus used in this study, the frequency of guau is really high, above all in young characters’ speech or in films or TV series addressed to a young audience. This tendency to calque English interjections and other expressions in the Spanish dubbed versions, something to be avoided in Gómez Capuz’s opinion, is much less frequent in original Spanish screenplays and in spontaneous colloquial Spanish, according to the results of this study.
Thawabteh (2010) examines the trans-latability of Arabic interjections in the English subtitles of an Egyptian film, State Security. Three main translation procedures were identified in this study, namely translating the SL interjection by means of an utterance which contains no interjection at all, translating the SL interjection by a TL interjection, and rendering a SL fragment with no interjection by means of a TL interjection. The study concludes that, although certain technical issues specific of subtitling limit the subtitler’s options, in the case of interjections, usually being short words, the effect of these subtitling demands is minimal.
In Yi Jing and Peter Robert Rupert White (2016), a study on the subtitling of two interjections —hey and oh—into Chinese, it was concluded that there was a tendency to omit both interjections in the Chinese subtitles. There were significant differences, though, as the omission rate was much higher for oh. These observed differences, Jing and White (2016) claim, were due to the diverse functions these two interjections fulfil. Thus, the interpersonal function of hey might explain the higher frequency to translate it into the TL. Although to a lesser extent, the co-text surrounding the interjection may also condition whether the TL subtitles omit the interjection or not. In this sense, the presence of similar meanings in the co-text might favour the omission of the interjection in the TT. Chinese is also the TL in Xian (2015), another paper focusing on the translation of English interjections. Three different translation methods are identified in this study, namely sound translation method, tone translation method and context translation method.
There is a group of studies focusing on the translation of interjections in drama, such as Alireza Shahraki, Amin Karimnia and Habibollah Mashhaddy (2012), Mona Farhoudi (2012) or Anna Drzazga (2019). Thus, Shahraki, Karimnia and Mashhaddy (2012) focus on the translation of interjections from English into Persian in ten theatre plays from the perspective of Skopos theory. The results of this study show that Iranian translators have most frequently resorted to literal translation to render English interjections in Persian. Similarly, Farhoudi (2012), another study on the translation of English interjections in a parallel English-Persian corpus of drama, found that the commonest translation solution was literal translation, followed by omission. Drzazga (2019), in turn, is centred on a particular play, Shakespeare’s Hamlet, and analyses the translation of interjections in three Polish versions of the Shakespearian drama. The most frequent translation solutions in this study have been proved to be, in this order, omission, the translation by an interjection with a dissimilar form and a similar meaning, and literal translation.
3. METHODOLOGY
3.1. Objectives
As explained above, the main objective of the present study is to analyse the translation of three primary and three secondary interjections in the BETA corpus, and English-Spanish corpus of subtitles. In addition, the following specific objectives have been established:
- To determine whether the type of interjection variable (primary vs secondary) conditions the selection of translation solution.
- To investigate whether translation solution choice and specific interjection are dependent or unrelated variables.
3.2. Research stages
The different stages followed in the empirical part of this study have been the following ones:
- Retrieval of all the examples of the six interjections mentioned above from the BETA corpus. As mentioned above, 991 tokens of the 6 interjections have been extracted from the corpus.
- Identification, classification and codification of the translation solutions adopted in each case. The data encoding is explained in sub-section 3.4 below.
- Application of the chi-square independence test in order to determine whether the analysed variables affect the adoption of translation solution.
- Analysis of the results and drawing of conclusions.
3.3. Description of the corpus
The BETA corpus is hosted at the CLUVI corpus, “an open collection of human-annotated sentence-level aligned parallel corpora developed by the SLI [Computational Linguistics Group] at the University of Vigo,” as described at the corpus website 2. This collection, with over 49 million words, contains 23 parallel corpora in different language combinations of languages such as Galician, English, Spanish, Portuguese, Catalan, Basque, French, or Chinese, and 9 specialised domains, among which fiction, law, biblical texts, tourism, economy, or subtitling are included. The segmentation unit used for alignment in the CLUVI corpus is the orthographic sentence, as explained by Xavier Gómez Guinovart and Elena Sacau Fontenla (2004). Within the CLUVI corpus, the BETA corpus is an English-Spanish parallel corpus of subtitles from 8 TV series and 4 films. Namely, the TV series are House (H), Nurses Who Kill, The Night Shift (T), Unrest (U), Big Mouth (M), BoJack Horseman (B), Family Guy (P), and The End of the F***ing World (E), and the 4 films are Fire in the Blood (FLS), Prescription Thugs (MCR), Resistance (RST), Unrest (URT) and The C Word (TCW) 3.
Figure I. First results of the search of wow in the BETA Corpus.
The corpus consists of 820,393 words, out of which 443,613 correspond to the SL—English—and 376,780 to the TL—Spanish—and it contains 59,243 translation units. It involves, then, both intralingual and interlingual subtitling and it may be openly consulted for free at https://ilg.usc.gal/cluvi/index.php?corpus=22&tipo=6&lang=en. The subtitles were produced for Netflix, the well-known American streaming platform.
The BETA Corpus is also user-friendly, since, among other features, its search interface is very simple and easy to use. Moreover, it allows for searches of isolated words or sequences of words in the SL (English in this case), in the TL (Spanish in the BETA Corpus), or in both SL and TL simultaneously. In other words, true bilingual searches may be carried out in which a given term is used in the SL and another one in the TL. The retrieved results offer the searched terms in context, and that linguistic context, or co-text, may be expanded. Figure 1 portrays the first retrieved results of an English primary interjection, wow.
3.4. Data encoding
The translation solutions adopted in the corpus of study were analysed and four different types were identified, in such a way that every example was classified and assigned to one of the four translation solution types. Each of the translation solutions is illustrated below by two examples from the corpus of this study, one corresponding to a source text (ST) primary interjection (odd examples) and another one corresponding to a ST secondary interjection (even examples).
The first translation solution, literal translation, illustrated by examples (1) and (2), involves translating the ST interjection by means of a TT interjection with a similar form and normally a similar meaning. Another possibility, represented by examples (3) and (4), is to translate the ST interjection as a TT interjection which has a different form and generally a similar pragmatic meaning in the given context. ST interjections may also be translated by resorting to a textual fragment which is not an interjection, but which generally reflects a meaning equivalent to that of the ST interjection, as reflected in examples (5) and (6). And, finally, ST interjections may be omitted in the TT, in such a way that there is no TT counterpart, as examples (7) and (8) show. This classification of translation solutions roughly coincides with that used in Cuenca (2006). Three of the translation solutions also coincide with Matamala’s (2007) typology.
| Ex. | ST | TT | ID code |
| (1) | Wow, I’m convinced. This store could save lives. | ¡Guau! Estoy convencido. ¡Esta tienda salvaría vidas! | B12/221 |
| (2) | In this last segment... Shit, I can’t say this. | En esta última parte... Mierda, no me sale. | TCW/1573 |
| (3) | – Ugh, that’s worse.
– BoJack, I’m moving to Maine. |
– ¡Coño! ¿Quién me llama? Eso es peor.
– BoJack, me mudo a Maine. |
B08/132 |
| (4) | Damn, Paul, your sticky chest gave me blue balls. | Joder, Paul, ese pecho pegajoso me pone a cien. | M03/10 |
| (5) | Wow, Todd, are you sure we’re ready for that? | Un momento, ¿estamos listos para eso? | B04/269 |
| (6) | – The troops are jerks?
– Oh, God. |
– ¿Los militares, imbéciles?
– Vaya cagada. |
B02/316 |
| (7) | – Because this one’s in our emergency room.
– Ah, so it’s a proximity issue. |
– Este está en Urgencias.
– Es cuestión de proximidad. |
H03/32 |
| (8) | Damn, Krista, you this crazy when you’re not at work? I’d like to see you on a week-end sometime. | ¿Te pones igual de loca fuera del trabajo? Quiero verte un fin de semana. | T03/27 |
In all the examples the relevant words, both the ST interjections and the textual fragments which may be identified as their translations, appear in bold. Emphasis is mine. On the contrary, the code which identifies each example is provided by the BETA corpus. In the examples extracted from a TV series, a letter represents the TV series and the number following it refers to the TV series chapter. In the examples from films, three letters, instead, stand for the film title in the Spanish market, which sometimes coincides with the original title whereas on other occasions involves a translation into Spanish. After the slash there is a number which indicates the translation unit. Thus, in example (1), for instance, B12 stands for the twelfth chapter of BoJack Horseman, whereas TCW in example (2) refers to The C Word.
3.5. Statistical test
The statistical test adopted in this study has been the chi-square test, an independence test whose objective is to determine whether two given variables are related or independent. In order to attain this goal, the chi-square test evaluates what has been referred to as the null hypothesis. This hypothesis establishes that the observed differences for two categorical variables, rather than being statistically significant, are simply due to chance. In those cases in which the chi-square test does not permit to reject the null hypothesis, it will be concluded that the two variables are independent or not related. On the contrary, in those other cases in which the null hypothesis may be rejected thanks to the results of the statistical test, the conclusion will be that the two analysed categorical variables are mutually dependent. In other words, the results observed for one of the variables may be said in these cases to be conditioned by the results observed for the other variable. The P-value calculated by the chi-square test will measure, then, the probability that observed differences are the result of chance. In this sense, a very low P-value will correspond to a very high statistical significance. Whenever the P-value is lower than 0.05, it will be possible to reject the null hypothesis at a 95% confidence level. As among the objectives of the study it was pursued to analyse whether two variables affected the selection of translation solution, it was decided to resort to this independence test, after having counted on the counsel of a specialist in statistics.
4. RESULTS AND DISCUSSION
4.1. Overview
In general terms, as Figure 2 reflects, the most commonly used translation solution in the whole corpus to translate interjections has been omission, as reflected in examples (9) and (10). Thus, 45.2% of the ST interjections have no textual counterpart at all in the Spanish subtitles. Several factors can contribute to explain this finding. First and foremost, subtitling is an audiovisual translation modality which quite often inevitably requires a certain degree of text reduction. As indicated by Díaz-Cintas and Remael (2014, p. 145) in this sense, “[t]he written version of speech in subtitles is nearly always a reduced form of the oral ST. Indeed, subtitling can never be a complete and detailed rendering”. In addition, the fact that interjections do not convey referential meaning, but rather pragmatic meaning, makes them strong candidates to be omitted in case of necessity. Therefore, the space and time restrictions typical of subtitling, together with the lack of referential meaning of interjections, may explain why they are so often omitted in TL subtitles. Other aspects which might explain the high percentage represented by omission may be related to the difficulty of finding exact equivalents in the TL for the SL interjections on certain occasions, or even the lack of certainty regarding the pragmatic meaning expressed by the ST interjection in some contexts.
Following omission, the second most fre-quent translation solution, with 27.4% and represented by examples (11) and (12), is that in which the SL interjection is translated by means of a different interjection in the TL, closely followed by literal translation, illustrated by (13) and (14), with 24.3%. Finally, translating English interjections by means of words or phrases in Spanish which are not interjections, as in examples (15) and (16), represents only 3%. There are very few examples, then, in which subtitlers decided to translate interjections by means of textual fragments which involved no interjection.
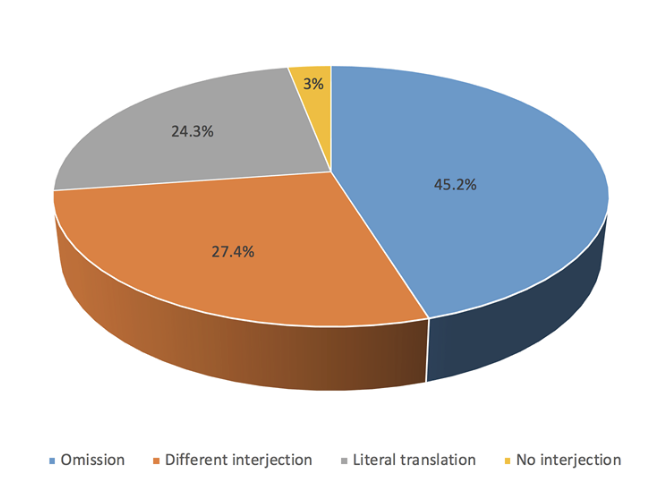
Figure 2. Translation solutions in the whole corpus.
4.2. Variables
In the previous subsection the raw results have been presented in the whole corpus, but these results can be fine-tuned to investigate whether variables such as the type of interjection—primary vs secondary—and specific interjection within each type had any effect on the choice of translation solution. It is precisely to the analysis of these two variables in relation to the selection of translation solution that the next subsections are devoted.
| Ex. | ST | TT | ID code |
| (9) | Wow. That must have been really tough. | Debió de ser muy duro. | M01/360 |
| (10) | Oh, shit, what these motherfuckers gonna do? | A ver qué hacen esos cabrones. | M02/54 |
| (11) | Ah! Lemur! | ¡Hostia, un lémur! | B03/213 |
| (12) | Oh, God... My leg. | Madre mía. La pierna. | T06/303 |
| (13) | Ah, because now you know you’re looking for a needle. | ¡Ah! ¿Ya sabes que buscas una aguja? | H04/525 |
| (14) | Oh, God, you’re upset about something. | Dios, a ti te pasa algo. | H06/298 |
| (15) | Ah. All right. | Sí. Claro. | T04/585 |
| (16) | Oh, my God, we just broke up. | Qué pesada, acabamos de cortar. | B01/258 |
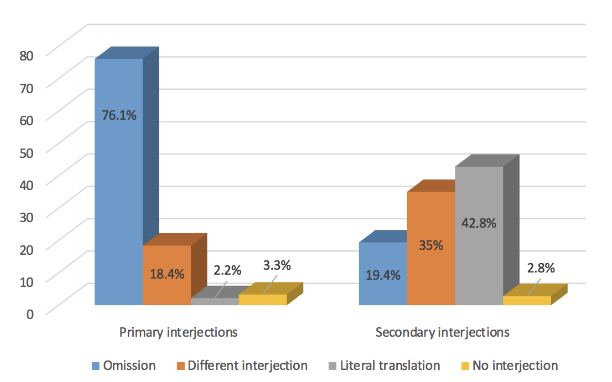
Figure 3. Translation solution by type of interjection.
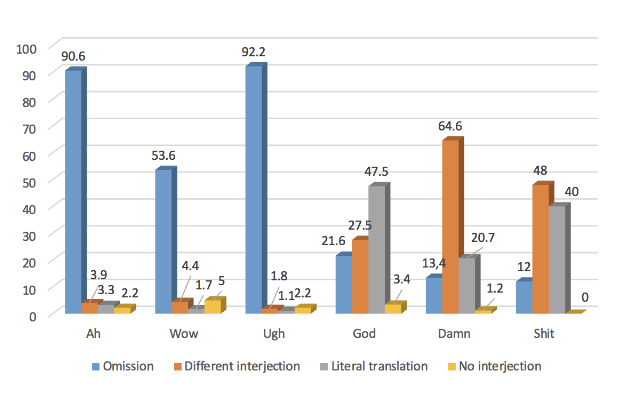
Figure 4. Translation solution by specific interjection.
4.2.1. Type of interjection variable
If, as stated above, omission has been found to be the most commonly adopted translation solution in the whole corpus, the situation changes if the different types of interjections are brought into the analysis. Thus, in the case of primary interjections (see Figure 3), omission is clearly, with a great difference, the preferred translation solution. More than three out of four SL interjections—specifically 76.1%—have disappeared from the Spanish subtitles. However, in the case of secondary interjections, omission occupies the third position in the rank of translation solutions. Less than one out of five secondary SL interjections—19.4%—have no corresponding textual fragment in the TT. The most commonly used translation solution to render secondary interjections has been literal translation—with 42.8%—, whereas this translation solution ranks fourth for primary interjections, representing only 2.2% of the cases in this type of interjection.
These substantial differences, which can be perceived by only glancing at Figure 3, may be foreseen to be statistically significant. In fact, the results of the chi-square test come to confirm this intuition. As Table 7 in the appendix portrays, P-value is lower than 0.05 (p<0.05), which indicates that type of interjection and choice of translation solution are related or mutually dependent variables. The null hypothesis, then, may be rejected at 95% confidence level. In other words, the choice of translation solution has been proved to be conditioned by the type of interjection, primary versus secondary.
4.2.2. Specific interjection variable
Figure 4 reflects the translation solutions adopted in this corpus across the six different interjections analysed in the present study. The first aspect which stands out is that for the three primary interjections omission is clearly the dominant translation solution, with percentages higher than 50% and for two of them higher than 90%, whereas for the three secondary interjections omission is the third translation solution, with percentages between 21.6% and 12%. It may also be observed that, whereas the patterns across the three primary interjections are more similar, notwithstanding obvious differences with respect to percentages, in the case of the secondary interjections there is much more diversity with regard to the choice of translation solutions.
| Form | N | % | N | % | |
| Ah | Ø | 163 | 90.6 | 180 | 100 |
| Ah | 6 | 3.3 | |||
| Sí | 2 | 1.1 | |||
| Ay | 1 | 0.5 | |||
| Eh | 1 | 0.5 | |||
| Ay, madre | 1 | 0.5 | |||
| Joder | 1 | 0.5 | |||
| Hostia | 1 | 0.5 | |||
| Vaya | 1 | 0.5 | |||
| Pero | 1 | 0.5 | |||
| No | 1 | 0.5 | |||
Tables 8 and 9 in the appendix show the results of the chi-square test, according to which there exists a mutually dependence relation between specific variable and translation solution within both the primary and secondary interjections groups. The null hypothesis can then be rejected in both cases, as p<0.05. In the following sub-sections each of the interjections is dealt with separately.
4.2.2.1. Ah
As for the rest of the primary interjections, the most frequent translation solution to tackle the rendering of ah in the Spanish subtitles is omission, illustrated by (17), with a percentage of 90%. After that, the next translation solution, represented by (18), involves a literal translation, in such a way that this interjection was translated into Spanish as ah in 3.3% of the cases. For the rest of the renderings (See Table 1), none of them reaches a percentage higher than 1.1%. Translators must have thought that in the majority of cases the pragmatic meaning might be inferred thanks to the situational context with the support of the visual semiotic channel, and therefore, it was unnecessary to offer a textual counterpart of the interjection in the Spanish subtitles.
Table 1. Translations of ah in the corpus.
| Ex. | ST | TT | ID code |
| (17) | Going home and watching porn again? Ah, yes. The student has become the master. Oh, that would make a pretty good porn. | ¿Volviendo a ver porno? Sí. El estudiante ha superado al maestro. Esa sería una buena porno. | M10/110 |
| (18) | – Can we go feed the ducks?
– Ah, ducks! Sounds good. – No, James. I said. |
– ¿Dar de comer a los patos?
– Ah, los patos, suena bien. – No, James. He dicho… |
E05/9 |
4.2.2.2. Wow
Again, this interjection was omitted in the majority of the cases, but the percentage, 53.6%, as shown in Table 2, is much lower than that seen for ah. Example (19) reflects this translation solution. Out of the three primary interjections focused on, the only one which has a textual counterpart with a percentage above 3.3% is wow. In the case of this interjection, the textual counterpart which reaches a higher percentage—specifically 26%—is vaya, which, according to the Diccionario de la Real Academia Española, may express both satisfaction or the opposite, disappointment or displeasure, and which is illustrated by (20). Wow, on the other hand, as defined in the Oxford English Dictionary, nowadays in general use expresses astonishment or admiration. The next translation in frequency, with 5% and exemplified by (21), is caray, interjection which in the above-mentioned Spanish dictionary is defined as expressing surprise or anger. The literal translation of wow as guau, which Gómez Capuz (1991) considers an Anglicism and an approximate phonic adaptation of its English counterpart, has been used as a translation only in 1.7% of the occurrences of wow in the corpus of this study.
| Form | N | % | N | % | |
| Wow | Ø | 97 | 53.6 | 181 | 100 |
| Vaya | 47 | 26 | |||
| Caray | 9 | 5 | |||
| Hala | 3 | 1.7 | |||
| Guau | 3 | 1.7 | |||
| Cielos | 2 | 1.1 | |||
| Jo | 2 | 1.1 | |||
| Jopé | 1 | 0.5 | |||
| Caramba | 1 | 0.5 | |||
| Uf | 1 | 0.5 | |||
| Coño | 1 | 0.5 | |||
| Ay, madre | 1 | 0.5 | |||
| Dios | 1 | 0.5 | |||
| Venga ya | 1 | 0.5 | |||
| Mola | 1 | 0.5 | |||
| Pues | 1 | 0.5 | |||
| O sea | 1 | 0.5 | |||
| Increíble | 1 | 0.5 | |||
| Un momento | 1 | 0.5 | |||
| Gracias | 1 | 0.5 | |||
| Muy bueno | 1 | 0.5 | |||
| A ver | 1 | 0.5 | |||
| Ya veo | 1 | 0.5 | |||
Table 2. Translations of wow in the corpus.
| Ex. | ST | TT | ID code |
| (19) | – Ninety per cent.
– Wow. That’s crazy. |
– Noventa por ciento.
– Qué locura. |
M01/360 |
| (20) | – How old is she?
– Thirty-two. – Wow. And she’s already the C.E.O. of a public company. |
– ¿Qué edad tiene?
– 32. – Vaya. ¿Y ya dirige una empresa que cotiza en bolsa? |
TCW/873 |
| (21) | – Look. They’re nodding. That’s the executive version of laughing.
– Wow. They must be serious about Herb. |
– Mira, mueven la cabeza. Así es como se ríen los ejecutivos.
– ¡Caray! Se ve que están muy interesados en Herb. |
B08/58 |