:: TRANS 26. MISCELÁNEA. Audiovisual. Págs. 181-199 ::
El subtitulado para personas sordas en las series en streaming: un estudio de corpus de inglés y español
-------------------------------------
Silvia Martínez Martínez
Universidad de Granada
ORCID: 0000-0003-0388-4035
Cristina Álvarez de Morales Mercado
Universidad de Granada
ORCID: 0000-0002-8298-8686
-------------------------------------
En este artículo se ofrecen los resultados de un estudio de corpus de series en español y en inglés con subtitulación para sordos (SpS). Las series en streaming empiezan a estar muy presentes en el mercado audiovisual y, en este sentido, entendemos que es necesario llevar a cabo una revisión sistematizada de esta nueva modalidad de traducción accesible. El objetivo principal de este trabajo consiste en analizar los sonidos articulados y no articulados que los subtituladores profesionales, tanto en inglés como en español, seleccionan en sus subtítulos. Así pues, pretendemos además identificar si hay semejanzas y/o diferencias entre estas dos lenguas en la práctica de dicha subtitulación. La metodología del presente trabajo se basa en un estudio de corpus compuesto por cuatro episodios de una serie en lengua inglesa y cuatro episodios de dos series en lengua española. Por último, con este análisis intentaremos arrojar datos fiables que nos sirvan para detectar las técnicas de traducción más utilizadas en lengua inglesa y en lengua española en el SpS.
PALABRAS CLAVE: Subtitulado para sordos, traducción audiovisual, accesibilidad, estudio de corpus, técnicas de traducción.
Subtitling for the deaf and hard-of hearing in streaming TV series: an English and Spanis corpus study
In this paper, we present results from a corpus study that consists of Subtitles for the Deaf and Hard-of-Hearing (SDHoH) in English and Spanish TV-Series. Streaming series have begun to take over the audiovisual market. In this regard, we consider essential the need of create a set of rules of this new modality of accessible translation. The main objective of this work is to carry out a general statistical analysis of the articulated and non-articulated sounds that professional subtitlers select, both in English and Spanish, to translate in their subtitles. Thus, we also aim to identify whether there are similarities and/or differences between these two languages in the practice of subtitling. The methodology of this work is based on a corpus study composed of four episodes of an English-language series and four episodes of two Spanish-language series. In addition, we also aim to identify whether there are similarities and/or differences between these two languages in the translation practice of subtitling. Finally, this analysis will provide us with reliable data that will help us to detect the translation techniques most used in English and Spanish in SDHoH.
KEY WORDS: Subtitles for the Deaf and Hard-of-Hearing, audiovisual translation, accessibility, corpus study, translation techniques.
-------------------------------------
recibido en noviembre de 2021 aceptado en marzo de 2022
-------------------------------------
1. Introducción
Hoy en día, la relación que tienen los usuarios con los contenidos audiovisuales ha sufrido un gran cambio. Hace apenas unas décadas, prácticamente solo se veían películas en el cine y la televisión. Actualmente, gracias al innegable auge de las plataformas en streaming existe la creciente tendencia de disfrutar de estos productos audiovisuales también en dispositivos móviles u ordenadores. Según el último Panel de hogares de la Comisión Nacional de los Mercados y la Competencia (CNMC) publicado en noviembre de 2020, la mitad de los hogares con acceso a Internet usa alguna de las plataformas digitales de pago para ver vídeos bajo demanda. Son ya numerosos los autores que se han sumado a explicar el porqué de este boom desde diferentes puntos de vista, como el tecnológico (Davies, 2016) o el económico (Lindsey, 2016).
De igual modo podemos hablar de la transformación y evolución del subtitulado (SB) en los productos multimedia. En sus inicios, el SB se centraba básicamente en plasmar los contenidos del diálogo de los personajes e incluso algunas empresas decían ofrecer subtitulación para sordos (SpS) a pesar de que este no cumpliera los parámetros mínimos de calidad para un producto accesible (Martínez-Martínez, 2015). Afortunadamente, con el transcurso de los años, el SpS ya no solo se centra en transcribir literalmente u ofrecer un recuento semántico de los diálogos, sino que también traduce los efectos sonoros y la música; hecho que, por supuesto, beneficia al usuario con diversidad funcional auditiva y que, al igual que el público “normoyente”, demanda cada vez más un SpS de calidad y lo exige en todas las plataformas en streaming, que tanto están de moda.
Asimismo, tal como señalan (Martínez-Martínez et al., 2019, p. 412), estos productos audiovisuales “han creado un mercado de trabajo urgente para la subtitulación y el SpS”. Es decir, las empresas, ya sean productoras, distribuidoras, etc. se encargan de contratar a profesionales de la traducción no solo para subtitular, sino también para que estos traduzcan los subtítulos de todos aquellos productos que se producen en streaming a diferentes lenguas. No obstante, a lo largo de este trabajo observaremos que el SpS no se lleva a cabo de manera uniforme en España ni en Estados Unidos, tanto en la cantidad de productos audiovisuales ofrecidos con SpS como en la calidad de estos. Muestra de ello es que en NetflIX contamos con 871 películas y series en inglés (EN) con SpS (SD, en sus siglas en inglés) y en español (ES) solo disponemos de 49 películas y series con SpS.
Teniendo en cuenta la importancia que hoy en día se le otorga a la calidad de los productos audiovisuales, el modo más adecuado de conseguirla, entre otros métodos, es realizar un estudio de corpus comparativo que nos permita comprobar qué sonidos son los que selecciona el subtitulador profesional del texto origen, entendiendo como tales sonidos tanto articulados como no articulados, para poder explicar además cuáles son las técnicas de traducción que emplea para trasladarlos a los subtítulos.
Los objetivos que nos proponemos en este trabajo son los siguientes:
- Realizar un análisis estadístico general sobre aquellos sonidos que el subtitulador profesional selecciona tanto en inglés como en español. Para el análisis del corpus trabajaremos con cuatro episodios de la serie Strangers Things (Duffer et al., 2016) en inglés, dos episodios de Élite (Salazar y de la Orden, 2018) y dos episodios de La casa de papel (Pina, 2017) en español. El género de todas las series es el thriller, que se caracteriza por una trama con una elevada dosis de suspense.
- Analizar desde el punto de vista intersemiótico, si son recurrentes en el SpS las siguientes técnicas traductológicas, a saber, categorización, atribución, explicitación, omisión y transcripción.
- Arrojar datos que nos permitan entender si el subtitulado en inglés y en español se ciñe a las directrices establecidas para su uso y aplicación en productos audiovisuales subtitulados. Para el español se hará referencia, por tanto, a la Norma UNE 153010 (2012) y para el inglés nos basaremos en el Described and Captioned Media Program (DCMP) (2019) de Estados Unidos1. Estos datos se comprobarán a través de la etiqueta tipografía (normativa y no normativa)
- Identificar qué técnicas de traducción son las más utilizadas en el corpus de estudio. Entendiendo que las técnicas traductológicas que mejor funcionan en esta tipología textual desde la perspectiva intralingüística son la traducción literal2, eliminación, condensación y la simplificación, es decir, las clásicas técnicas de traducción propias de la traducción intralingüística (Martínez-Martínez, 2015). A partir de este momento, ofreceremos un acercamiento teórico a los estudios de corpus y expondremos la metodología de este trabajo, además arrojaremos datos muy interesantes para el estudio que nos permitirán analizar los resultados más relevantes extraídos del análisis.
2. Un acercamiento teórico: estudios de corpus multimodales anotados sobre SpS
Los estudios de corpus se han aplicado a diferentes modalidades de traducción para entornos multimedia (TEM), y los resultados que todos ellos han aportado han tenido una gran relevancia en la investigación de esta nueva modalidad de traducción. Podríamos hablar también de un auge parecido al que están teniendo actualmente las plataformas en streaming con los estudios de corpus, tal como señalan Baños Piñero y Díaz-Cintas (2015), o Valentini (2006, p. 68), quien incluso afirma que utilizar un corpus hoy en día se ha convertido en algo estrictamente necesario en todo análisis lingüístico:
The last decade has witnessed a massive growth in the creation and use of corpora, which have arguably become the necessary hallmark of all scientific linguistic analysis. Electronic corpora nowadays provide the basis for empirical research in translation-based studies, with positive repercussions which have long been discussed in the literature from a theoretical, practical and pedagogic point of view.
Así pues, en este trabajo nos hacemos eco también de la importancia que tiene utilizar estudios de corpus apoyados en una metodología determinada como es la escogida para nuestro análisis.
Aunque existen ya estudios de corpus extensos en otras áreas de TEM, tales como el corpus TRACCE (Jiménez Hurtado, 2010) en audiodescripción, el de doblaje (Valentini, 2008) o subtitulación para normoyentes (Martí Ferriol, 2013), a partir de ahora, nos centraremos en los estudios de corpus existentes en una de las modalidades de TEM más demandada en la actualidad: el SpS.
A diferencia de los tipos de traducción anteriormente mencionados, los estudios de corpus sobre SpS son en su mayoría estudios de caso compuestos por una o dos películas o algunos extractos de programas televisivos (Kalantzi, 2008; Zárate, 2014). No obstante, podemos afirmar, sin embrago, que, a partir del año 2015, existen estudios de corpus más extensos. Entre ellos destacamos el análisis de 30 películas sobre las técnicas de traducción utilizadas en SpS en España realizado por Martínez-Martínez (2015), el de 15 películas en portugués brasileño de Pessoa de Nascimiento (2017), el análisis descriptivo de carácter cualitativo del SpS en español y alemán de 19 películas (Cuéllar Lázaro, 2020), además de diversos estudios de corpus realizados en Trabajos Fin de Grado que versan sobre el estudio de algunas series en streaming en inglés de la plataforma NetflIX como el de González López et al. Martínez (2018), entre otros.
Para realizar nuestro estudio de corpus, nos hemos basado en el etiquetado semántico de SpS que fue creado por Martínez-Martínez (2015) y que es uno de los pilares metodológicos de este trabajo. El objetivo principal del sistema de este etiquetado es identificar, analizar y clasificar los elementos acústicos (verbales y no verbales) del texto origen que el traductor ha considerado relevantes para el significado multimodal del producto audiovisual y relacionarlos con las técnicas de traducción interlingüística, intralingüística o intersemiótica empleadas para su traslado al subtítulo.
El desarrollo de un marco conceptual para crear un sistema de etiquetado semántico es una tarea extremadamente compleja. Para tal fin, la autora elaboró dos niveles de etiquetas. Un primer nivel (El contenido audio) en el que se anota aquella información que los subtituladores seleccionan del modo audio del texto original (sonido articulado y no articulado) y traducen en un sistema verbal, el subtitulado. Se analizan, por tanto, las características y funciones más destacadas de la banda sonora, subdividida en segmentos estructurales como el diálogo de los personajes, sus elementos paralingüísticos, la música y finalmente, los efectos sonoros.
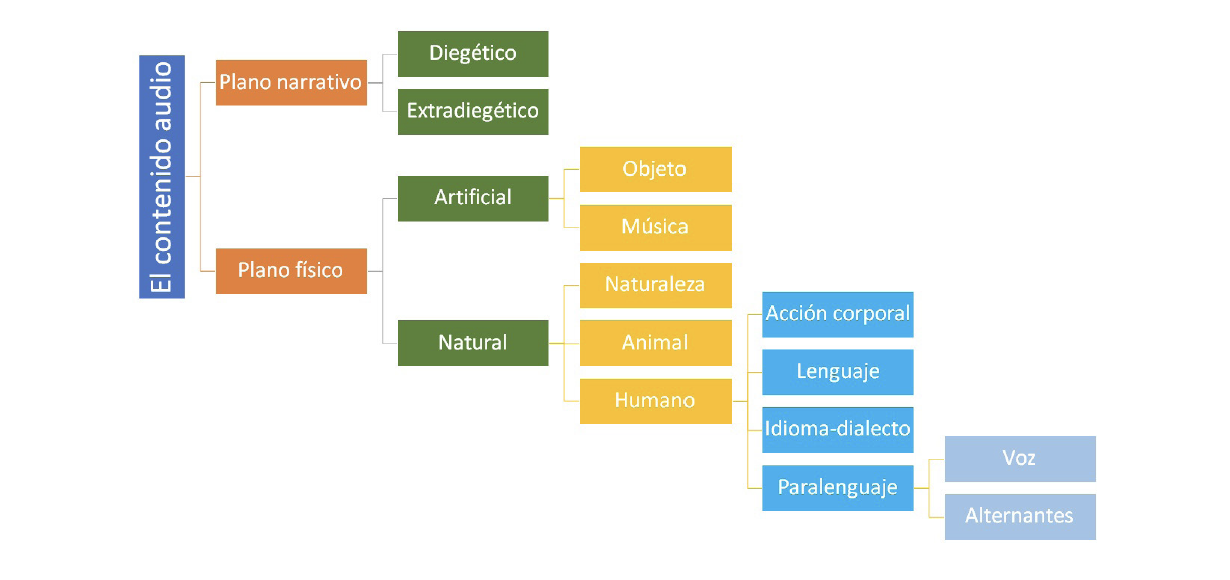
Fig 1. Conjunto de etiquetas del Nivel 1: El contenido audio.
Y un segundo nivel de etiquetas que recoge la aplicación de las técnicas de traducción, es decir, analiza el proceso traductor y muestra las preferencias traductoras de los profesionales. El sistema de anotación de las técnicas de traducción tiene la finalidad de identificar y clasificar las técnicas empleadas en la traducción de los elementos del nivel anterior, tanto en la traducción interlingüística e intralingüística del lenguaje como en la traducción intersemiótica de las categorías paralingüística y no verbales del sonido fílmico descritas anteriormente. La clasificación de las técnicas de traducción intralingüística de SpS se basan en estudios sobre SB y SpS (Neves, 2005; Martínez-Martínez, 2015; Martí Ferriol, 2013; Cabo Villarpriego, 2008).
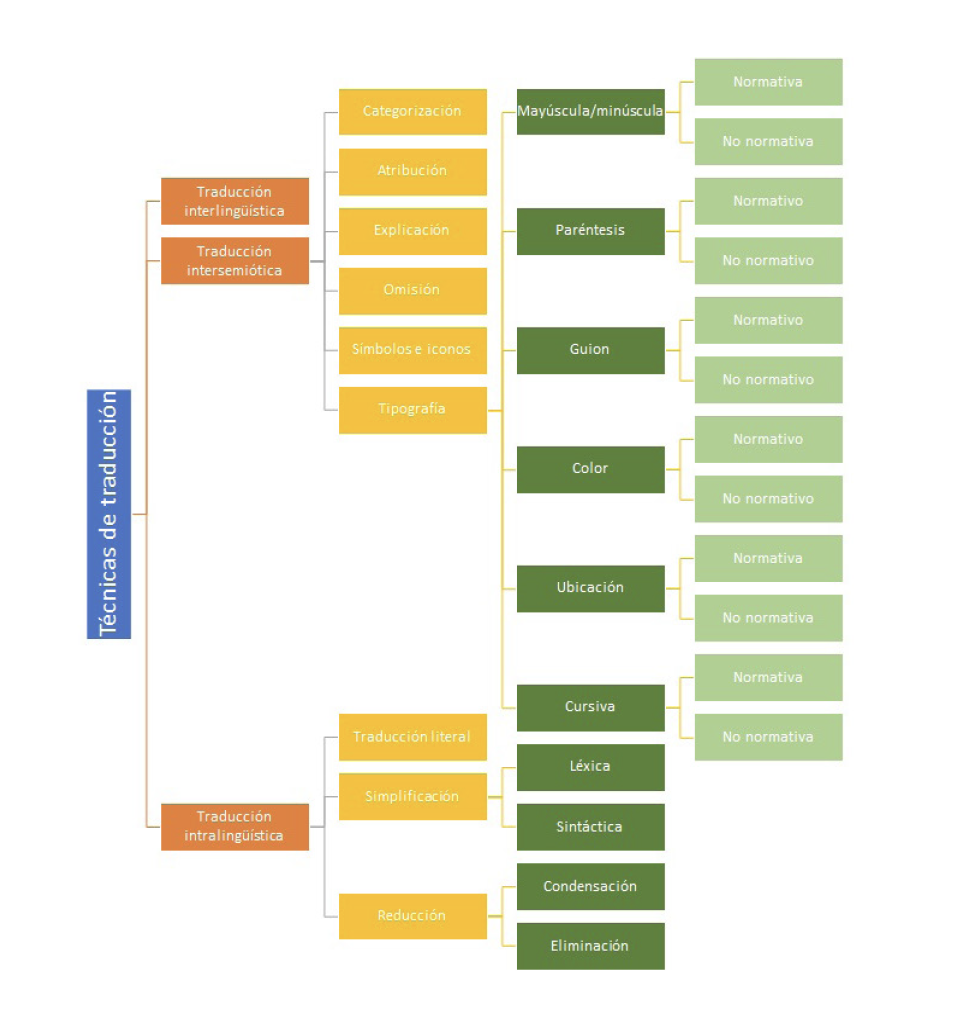
Fig 2. Conjunto de etiquetas del nivel 2: Técnicas de traducción.
Este nivel está formado por tres grandes bloques: traducción interlingüística, traducción intersemiótica y traducción intralingüística. Puesto que la primera clasificación no se divide en más técnicas de traducción, procederemos a explicar seguidamente los dos últimos bloques.
La división perteneciente a la traducción intersemiótica está formada por siete técnicas de traducción (Martínez-Martínez, 2015):
- Categorización: consiste en la asignación de un sonido o la acción que produce un sonido a una categoría conceptual. Responde a las preguntas: ¿Qué es? (Puerta), o ¿Qué hace? (Frena).
- Atribución: consiste en la caracterización de un sonido por medio de la asignación de propiedades o atributos. La atribución implica o requiere la categorización previa del sonido, que se complementa con una o varias propiedades que lo describen en mayor detalle. Así pues, esta técnica atribuye a lo categorizado una cualidad como, por ejemplo, sustantivo + adjetivo (música melódica), sustantivo + adverbio (timbre insistentemente) o un adjetivo (decepcionada).
- Explicación: consiste en la explicitación de información relacionada con la producción de un sonido que no constituye una propiedad o atributo de este. Normalmente, esta información se refiere al origen del sonido. Es decir, la acción llevada a cabo por un personaje que produce el sonido en cuestión cuando dicha acción implica la manipulación de un objeto, o incluso la duración el mismo, indicación del comienzo y el final de un sonido (Fin de la música).
- Omisión: consiste en la omisión en el subtitulado de un sonido del texto origen que se considera relevante para la comprensión del producto audiovisual.
- Transcripción: se trata de la transcripción de un sonido propiamente dicho, como muac en vez de beso. Además, se suele utilizar con determinados tipos de interjecciones (ah, oh, eh) y onomatopeyas (guau).
- Símbolos e iconos: consiste en el uso de estos para traducir un sonido. Un ejemplo de ello es el símbolo ♪ que se utiliza para indicar la letra de una canción.
- Tipografía: esta técnica de traducción intersemiótica se divide en seis técnicas de traducción que hacen referencia a los aspectos ortotipográficos que figuran en las pautas de la Norma UNE 153010 (2012). Estas son: mayúscula/minúscula, paréntesis, guion, color, ubicación y cursiva. Estas seis técnicas se dividen a su vez en uso normativo y no normativo, según la norma AENOR (2012: 8-12) anteriormente mencionada.
Por último, en la traducción intralingüística, nos encontramos con cuatro técnicas de traducción, que, recordemos, son las clásicas señaladas por autores de referencia como propias del subtitulado, tanto el de normoyentes como del SpS (Martínez-Martínez, 2015):
- Traducción literal: que consiste en la transcripción verbatim de los diálogos de los personajes.
- Simplificación: que consiste en emplear un léxico o sintaxis más sencillos en el subtítulo que los utilizados en los diálogos. Esta técnica, por lo tanto, también se divide en dos: simplificación léxica (barco en vez de galera) y simplificación sintáctica (Audio: Me pregunto a qué estarán esperando para venir a buscarlos. SpS: Me pregunto a qué esperan para venir a buscarlos.).
- Reducción: que consiste en una reducción del contenido de los diálogos en el subtítulo. Esta reducción puede consistir en un resumen de los diálogos o condensación (Audio: Cuando el Rey lo ordene me pondré a disposición de la Corona, como he hecho siempre. SpS: Cuando el Rey lo ordene me pondré a su disposición, como he hecho siempre. o en la eliminación de parte de estos (Audio: Sí, sí… Se trata de un antiguo caserón de finales de siglo. SpS: Se trata de un antiguo caserón de finales de siglo.).
A estas tres técnicas tan habituales en la traducción intralingüística se han añadido otras novedosas técnicas de traducción intersemiótica, a saber, la categorización, atribución y explicación Martínez-Martínez (2015) pues son, en nuestra opinión, las que mejor reflejan la labor que realiza el subtitulador profesional a la hora de verbalizar todos aquellos sonidos que no son articulados.
Tal como afirman Martínez-Martínez et al. (2019, p. 415) estos dos niveles “forman parte de una metodología que ha resultado ser un hallazgo importante, ya que permite conocer las relaciones entre lo que se traduce y cómo se traduce”. Conviene señalar que hasta el momento este etiquetado semántico se ha utilizado para ofrecer resultados sobre el SpS en España y que su creación se hizo esencialmente para tal fin. No obstante, este etiquetado se tradujo al inglés y al alemán y se comprobó que se podía utilizar perfectamente para analizar el SpS de estas lenguas.
3. Una aproximación metodológica: Corpus de trabajo
Para el proceso de anotado, nos decantamos por el programa MAXQDA por su flexibilidad, opciones de análisis y exportación de datos, así como por su usabilidad. Se trata de un software pionero en el análisis cualitativo de datos de texto por medio de una variedad de recursos metodológicos: apoyo completo para los archivos PDF que serán mostrados exactamente como se muestra en Adobe Acrobat y además pueden ser codificados en MAXQDA; visualización como instrumento analítico; integración metódica de los procedimientos cualitativos y cuantitativos así como esquemas sincronizados de Audio/Video y transcripción de textos a través de un acceso directo a los datos de vídeo o audio originales (Álvarez de Morales Mercado, 2015).
Asimismo, este software ofrece varias opciones para el análisis de los resultados, siendo en esta ocasión muy importante la de “fusionar proyectos” para poder, en este caso, comparar los resultados del etiquetado de diferentes episodios.
Dado que la aplicación de las etiquetas se realiza de forma manual por diferentes etiquetadores, para el análisis se creó un protocolo de actuación consensuado entre etiquetadores pertenecientes al grupo de investigación TRACCE de la Universidad de Granada (tracce.ugr.es) con el fin de evitar excesivas divergencias en el proceso.
La parte fundamental de todo estudio de corpus es el proceso de etiquetado y que consiste en anotar las etiquetas correspondientes a cada uno de los subtítulos. Recordemos que el sistema de anotación del contenido audio consiste en una tipología del sonido basada en estudios fílmicos (Gorbman, 1987; Bordwell y Thompson, 2010, y Chion, 2008) y lingüísticos (Poyatos, 1994a). En este sentido Pérez Bowie (2004) insistía en que autores como Bordwell y Thompson, desde su metodología cognitivista interesada en aclarar los esquemas y procedimientos mentales, aplicados por los espectadores para inferir las historias que se les cuentan desde la pantalla, dedicaban gran atención a las fórmulas sobre las que se articulan los esquemas genéricos (Martínez-Martínez, 2015).
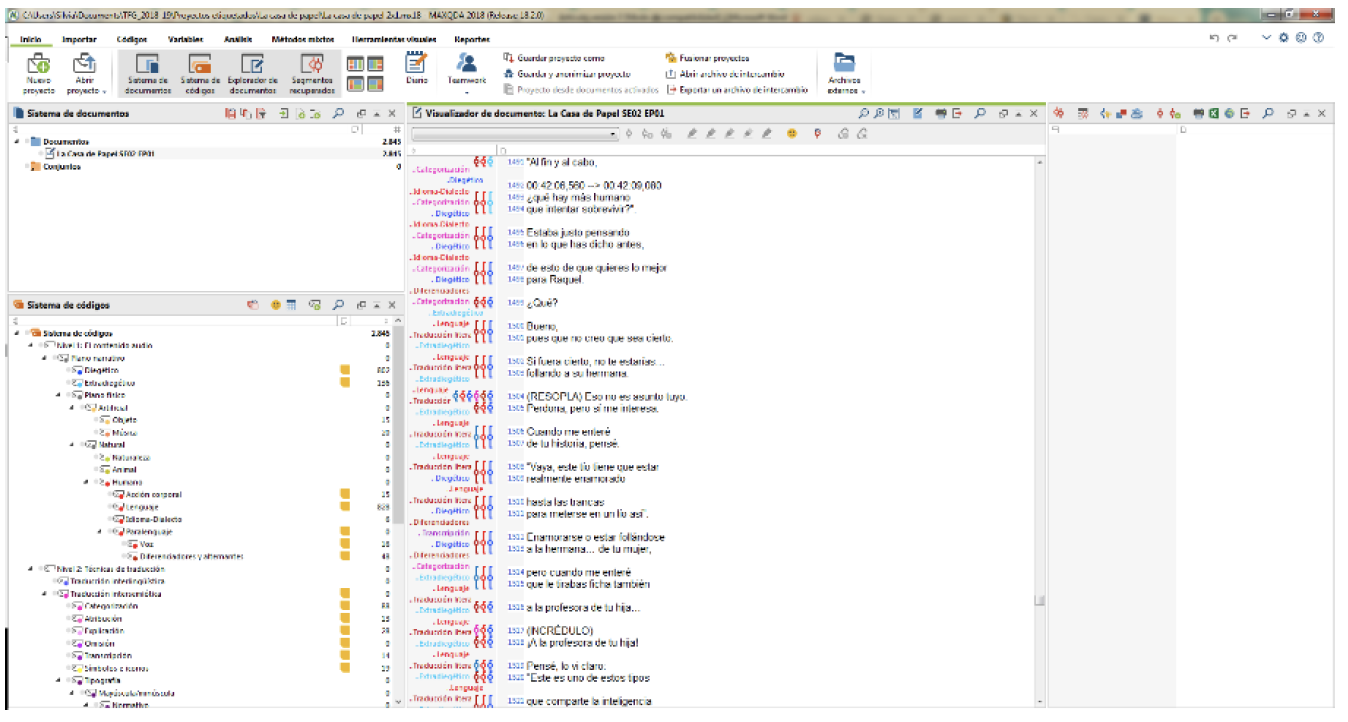
Fig 3. Interfaz del programa MAXQDA.
En la Figura 3 se muestra la interfaz del programa de análisis cualitativo empleado. En la parte izquierda podemos ver el árbol de etiquetas explicado en el apartado anterior y en la parte derecha figuran los subtítulos junto con sus etiquetas inmediatamente a su izquierda.
Cabe señalar que actualmente, el grupo TRACCE de la Universidad de Granada cuenta con más de 100 películas en español con SpS, 17 episodios de series en español, 20 episodios de series en inglés y 8 en alemán (Corpus TRACCE-SpS).
En esta ocasión, hemos decidido trabajar con un corpus compuesto por cuatro episodios en inglés de la primera temporada de la serie Strangers Things (Duffer et al., Levy, 2016) que son los que siguen: The Vanishing of Will Byers (T1: E1), The Weirdo on Maple Street (T1: E2), Holly, Jolly (T1: E3) y The Body (T1: E4); y, en español, dos episodios de la serie Élite (Salazar y de la Orden, 2018): Bienvenidos (T1: E1) y Deseo (T1: E2), y de La casa de papel (Pina, 2017): La casa de la marmota (T1: E5) y Se acabaron las máscaras (T2: E1).
El principal motivo de la elección de este corpus es realizar por primera vez un estudio comparativo para determinar qué sonidos se han identificado en el texto origen y qué técnicas de traducción se han utilizado en dos lenguas diferentes (inglés y español). Por otro lado, hemos visto conveniente iniciar estos tipos de análisis centrándonos exclusivamente en un solo género cinematográfico, el thriller. Se trata de un género en el que aparecen numerosos ruidos producidos por acciones y se ofrece, por lo general, un alto porcentaje de diálogos y sonidos musicales que nos provocan tensión y miedo. Todas estas características propias del género se ven reflejadas en sus subtítulos, tal como veremos en el siguiente apartado.
4. Análisis comparativo y resultados
Una vez explicado el proceso de etiquetado y anotación con el software MAXQDA, procedemos, en primer lugar, a la exposición de datos para seguidamente realizar una interpretación de estos.
Como ya hemos comentado anteriormente, se ha realizado el etiquetado semántico del corpus compuesto por episodios en inglés y en español de series en streaming de la plataforma NetflIX. Cada uno de los episodios cuenta con un número de subtítulos diferente, tal como podemos observar en los gráficos 1 y 2. No obstante, trabajaremos con un número de subtítulos más o menos equilibrado en ambas lenguas que conforman el corpus de estudio.
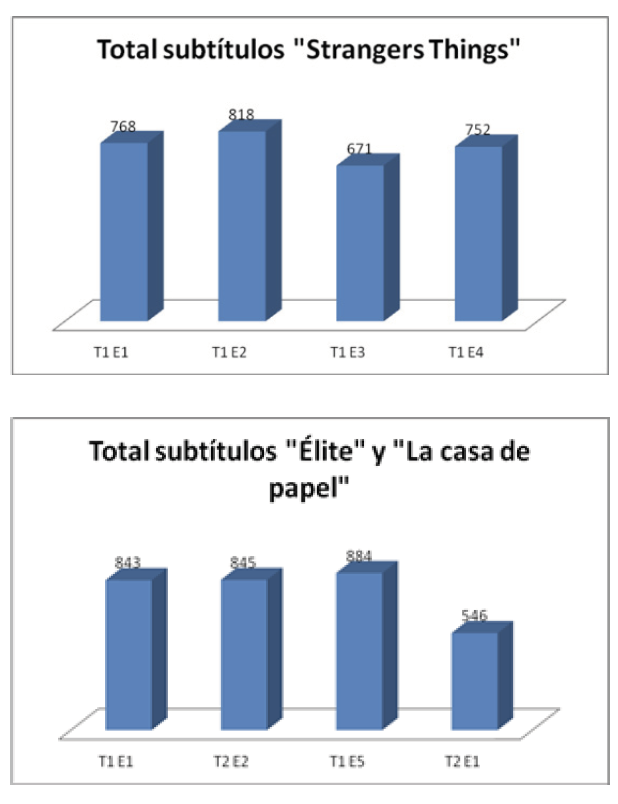
Gráficos 1 y 2. Número de subtítulos de los episodios en inglés y en español.
Debido a que cada uno de los episodios cuenta con una cantidad de subtítulos distinta (3009 subtítulos en inglés y 3118 en español), el número de segmentos codificados lógicamente variará en cada uno de ellos. Este hecho se debe principalmente a la cantidad de diálogo o cualquier otro tipo de sonidos traducidos que haya en cada uno de los capítulos, independientemente de la lengua de trabajo. En los siguientes gráficos (3 y 4) podemos observar el total de segmentos codificados en cada uno de los episodios que conforman este corpus.
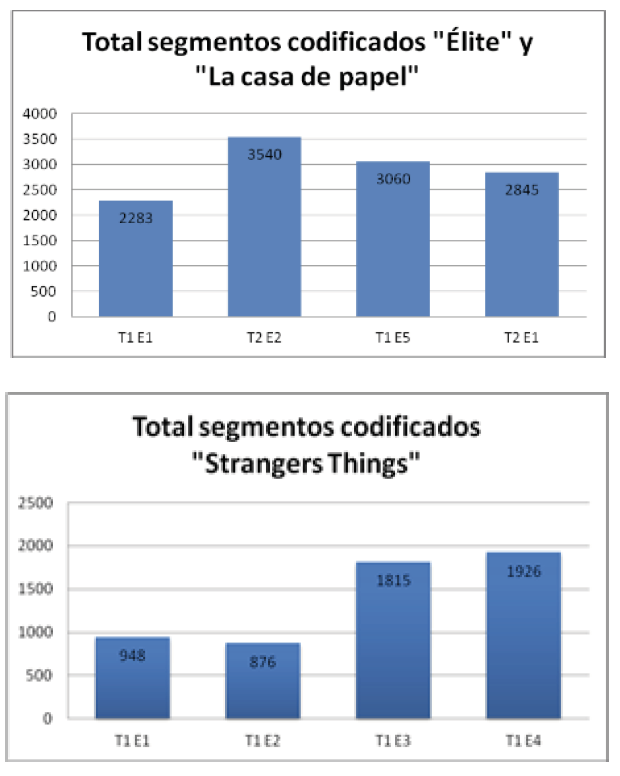
Gráficos 3 y 4. Segmentos codificados del corpus.
Una vez extraídos los datos relativos al número de subtítulos y de segmentos de codificación, procederemos a mostrar datos más específicos siguiendo la división por niveles (el contenido audio y técnicas de traducción) explicada en el segundo apartado.
4.1. Resultados del nivel 1: el contenido audio
El primer nivel está dividido en dos categorías, una que se refiere a los sonidos pertenecientes al plano narrativo y otra que se refiere a los sonidos procedentes del plano físico. La primera subdivisión contiene la etiqueta sonido diegético y sonido extradiegético. El sonido diegético es aquel cuya fuente de emisión se encuentra dentro del espacio narrativo del producto audiovisual. Son sonidos diegéticos los diálogos de los personajes, sonidos de la naturaleza y objetos del mundo en que se desarrolla la acción y la música, cuando la fuente se encuentra dentro de dicho mundo. El sonido extradiegético, por el contrario, se produce fuera del espacio narrativo o de la historia (Bordwell y Thompson, 2010); pertenecen a esta categoría todo aquello que los personajes no escuchan, como la narración (voz en off) y la música que acompaña la narración, pero no forma parte de esta.
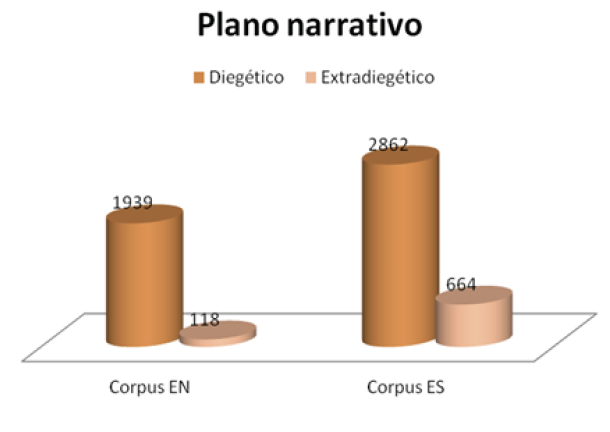
Gráfico 5. Comparación de subtítulos etiquetados en el plano narrativo.
Como se puede deducir del anterior gráfico, los episodios de las series en español son más ricos en sonidos, tanto diegéticos como extradiegéticos, que los de inglés. No obstante, se puede observar que los sonidos que se han plasmado mayoritariamente son aquellos que forman parte del espacio narrativo y no los que se encuentran fuera del mismo, esto es, los sonidos diegéticos. También conviene tener en cuenta que este fenómeno ocurre precisamente porque los productos audiovisuales están compuestos en su mayoría por diálogos, es decir, que la expresión verbal de los personajes es el componente más frecuente de la banda sonora fílmica.
Seguimos con la siguiente categoría del primer nivel, el plano físico que está dividida en ocho etiquetas o subdivisiones: objeto, música, naturaleza, animal, acción corporal, lenguaje, idioma-dialecto, voz y alternantes.
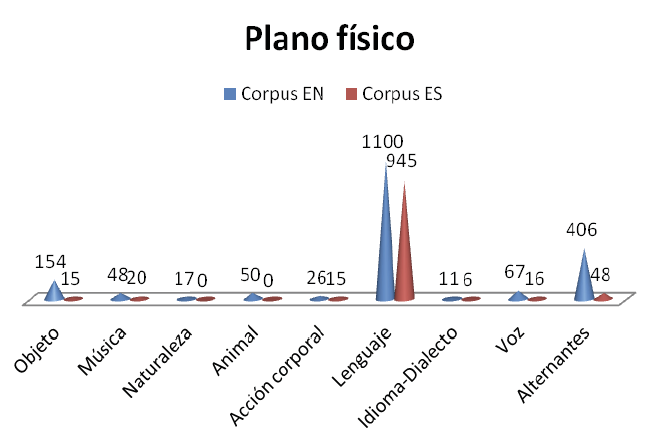
Gráfico 6. Comparación de subtítulos etiquetados en el plano físico.
Tal como se puede observar en el gráfico anterior, la etiqueta que cuenta con un mayor número de ejemplos es claramente la de la expresión oral o “lenguaje”, tal como se denomina a esta etiqueta en el sistema de etiquetado utilizado, algo que se debe al número elevado de diálogos presentes en las tres series.
Si nos fijamos en la Imagen 2, que recoge el árbol de etiquetado completo, nos daremos cuenta de que el segundo nivel de clasificación del sonido fílmico se ha dividido en las etiquetas de natural y artificial, cada una de las cuales se subdivide a su vez en varios tipos. La etiqueta de sonido natural incluye las etiquetas de “humano”, “naturaleza” y “animal”. La primera de estas se compone de los niveles o etiquetas “acción corporal”, “lenguaje” y “paralenguaje”: el primero se refiere a los diálogos (diegéticos) y la narración o voz en off (extradiegética) y la segunda, a las cualidades no verbales de la voz y sus modificadores y las emisiones independientes cuasiléxicas, así como los silencios momentáneos, que utilizamos consciente o inconscientemente para apoyar o contradecir los signos verbales, kinésicos, proxémicos, químicos, dérmicos y térmicos, simultáneamente o alternando con ellos, tanto en la interacción como en la no-interacción (Poyatos 1994b). Por último, la categoría de sonido artificial se subdivide en las etiquetas de “objeto y música”. De esta última hablaremos más adelante.
A esta etiqueta, le sigue “alternantes”. Este fenómeno se debe a la forma en que los protagonistas profieren las palabras o los sonidos y sus diálogos. Ejemplos como “respira” o “resopla”, en español y grunt o breathing, en inglés, han sido etiquetados como alternantes. Las alternantes además pueden recibir más de una etiqueta, como, por ejemplo, la de “acción corporal” o “voz. Después de visionar los episodios de este corpus, llegamos a inferir que esta etiqueta es mucho más frecuente en los episodios en inglés debido a que existen muchos más sonidos producidos por animales y seres humanos (llantos, risas, etc.). Esto también ocurre con la etiqueta de “voz”. Esta etiqueta incluye dos categorías: a) cualidades primarias de la voz, esto es, cualidades de la voz humana que nos diferencian como individuos, aunque puedan variar por diversos motivos: timbre, resonancia, intensidad o volumen, tempo, registro, campo de la entonación, duración silábica y ritmo, condicionadas por factores biológicos, fisiológicos, psicológicos, socioculturales y ocupacional; y b) calificadores de la voz, que son modificadores de la voz determinados por factores biológicos y fisiológicos, estos últimos afectados a su vez por variables psicológicas y emocionales. Pero su verdadera importancia reside en sus funciones socioculturales, ya que constituyen una complejísima serie de efectos de voz, controlables o no, percibidos y juzgados socialmente según valores establecidos universalmente (ejemplo, el susurro de intimidad) y culturalmente (por ejemplo, compresión o faringalización, seguidas de falsete en un “What?” británico de sorpresa e incredulidad). Son precisamente estos calificadores de la voz y del lenguaje de los personajes los que priman en el corpus en inglés. Veamos los ejemplos que aparecen a continuación.

Figuras 4 y 5. Ejemplos de “voz” en Strangers Things (Duffer et al., 2016), y en La casa de papel (Pina, 2017).
Asimismo, cabe señalar la existencia de muchos más objetos etiquetados en inglés. Por lo tanto, en esta lengua se tiene más en cuenta al usuario con diversidad funcional auditiva para que este acceda mejor al conocimiento de la trama e intenta mostrar en su subtitulado la mayor información no verbal posible.
En cuanto al sonido procedente de fenómenos de la naturaleza y sonidos producidos por animales, observamos que ocurre un caso muy parecido a los anteriores. En las series en español no se han traducido ninguno de estos sonidos, a pesar de que existen muchos. Este hecho lo hemos podido corroborar gracias al visionado exhaustivo de los episodios que conforman el corpus. En cuanto al sonido emitido por animales, no es de extrañar que haya más en inglés, ya que una de las figuras sobre la cual gira el eje argumental de la trama de la serie Strangers Things (Duffer et al., 2016) es el Demogorgon, una criatura humanoide depredadora, y que se ha etiquetado como “animal” a lo largo del corpus. El motivo principal de esta elección fue que el monstruo emite un sonido que siempre fue subtitulado como “growl” y este verbo se encuentra ligado al mundo animal según su definición (González López et al., 2018).
Por último, la etiqueta “música” arroja también unos datos bastante sorprendentes. A pesar de que todas las series cuentan con música a lo largo de sus episodios, observamos que en las series en inglés se le da mucha más importancia. De este modo, comprobamos que la serie estadounidense intenta trasmitir a la persona con diversidad funcional auditiva todas aquellas emociones que emanan de la trama audiovisual mientras que en las series en streaming subtituladas en español se suelen obviar con mucha más frecuencia.

Figura 7. Ejemplo de la etiqueta “animal” en Strangers Things (Duffer et al., 2016).
4.2. Resultados del nivel 2: Técnicas de traducción
Continuamos con el siguiente nivel, que, recordemos, identifica las técnicas de traducción que han utilizado los subtituladores profesionales para traducir los sonidos seleccionados en el nivel anterior. Este está dividido en tres grandes categorías: traducción interlingüística, traducción intersemiótica y traducción intralingüística.
En la primera de ellas, hemos observado que no existen casos de la primera categoría en inglés, sin embargo, este tipo de traducción sí se ha identificado en las series en español (38 etiquetas). Recordemos que en esta etiqueta se reflejan las traducciones de otras lenguas al español o al inglés (véase Gráfico 6). En este caso, creemos que este fenómeno se debe a que la trama de la serie en inglés no lo requiere. Evidentemente, el corpus de estudio debe ampliarse en un futuro para poder afirmar si esta tendencia es algo puntual o no.

Figura 8. Ejemplo de traducción interlingüística de La casa de papel (Pina, 2017).
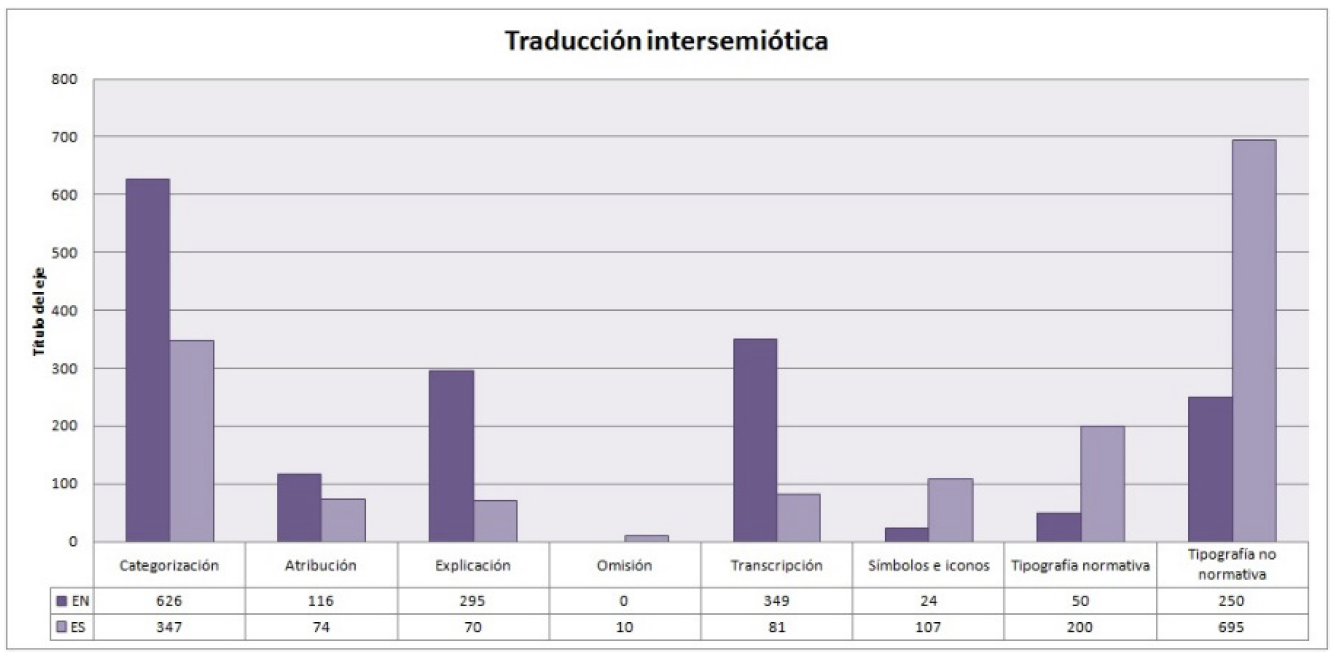
Gráfico 9. Resultados de las técnicas de traducción del nivel 2.
Continuamos con la traducción intersemiótica, que como ya hemos visto anteriormente, se trata del tipo de traducción que se utiliza para trasladar todos aquellos sonidos identificados en el nivel anterior para expresarlos en palabras. Esta división está formada por: categorización, atribución, explicación, omisión, transcripción, símbolos e iconos y tipografía. Esta última técnica está a su vez subdividida en mayúsculas/minúsculas, paréntesis, guiones, colores y ubicación. En este análisis, hemos sumado los resultados de estas subetiquetas (mayúscula/minúscula, paréntesis, guion, color, ubicación y cursiva) dividiéndolas solo en tipografía normativa y no normativa, esto es, que cumplan las directrices fijadas al respecto por las normas propias de cada lengua, tal como se puede observar a continuación.
Al mostrar los datos de las técnicas de traducción intersemiótica, observamos la variedad de las mismas, aunque algunas predominan claramente sobre otras. En primer lugar, destaca el uso de la tipografía no normativa (250 etiquetas en inglés y 695 etiquetas en español), es decir, los subtituladores profesionales no han seguido las pautas marcadas por la norma UNE 153010 (2012) ni las que figuran en la DCMP (2019) de Estados Unidos. Este hecho se puede deber en parte a que NetflIX dispone de unas directrices propias (en inglés3 y en español para España y Latinoamérica4) para realizar subtítulos que, deducimos, que son las que utilizan los profesionales de la subtitulación. No obstante, esta tendencia es mucho más significativa en español.
En cuanto a la transcripción observamos que esta técnica es más recurrente en inglés (349 etiquetas frente a las 81 en español). Como hemos visto anteriormente, en Strangers Things (Duffer Matt Duffer, Ross Duffer y Shawn Levy, 2016) existen más subtítulos sobre sonidos procedentes de la naturaleza y de los animales, así como sonidos que especifican los cualificadores de la voz humana y sus sonidos paralingüísticos. En este sentido hemos observado que los subtituladores del SpS en inglés han decidido transcribir el sonido propiamente dicho (Ah, Boo, etc.) y no categorizarlo, es decir, escribir su forma verbal (Grita) o nominal (Growls).
Si nos detenemos en la etiqueta símbolos e iconos, destaca su frecuencia en las series en español (107 etiquetas), mientras que en la serie en inglés la frecuencia de uso es de solo 24. Este fenómeno se debe básicamente a que existen más canciones que en la serie americana y, para identificarlas en el SpS, se ha utilizado el símbolo de la corchea (♪) para distinguir las letras de las canciones que son cantadas frente a las que no lo son. De hecho, en nuestro corpus este es el único símbolo que se ha identificado.
La omisión, que como sabemos, en este análisis consiste en la eliminación de un sonido presente en el texto origen para normoyentes, pero es relevante para la comprensión del producto audiovisual, aunquee el subtitulador profesional no la haya traducido. En español hay una recurrencia de 38 etiquetas, mientras que en inglés no existe ningún caso en el que se haya detectado el uso de esta técnica de traducción. Es más, convendría señalar que el SpS en inglés ofrece prácticamente la traducción de todos los sonidos relevantes para el seguimiento de la trama del producto audiovisual.
Por último, tenemos que hablar de las tres técnicas de traducción más novedosas en los estudios de corpus del SpS hasta la fecha, como son la categorización, atribución y explicación. En el gráfico podemos observar que en el corpus destaca el uso de la primera de ellas (626 en inglés y 347 en español), seguida de explicación (295 en inglés y 70 en español) y, por último, de atribución (116 en inglés y 74 en español). La categorización consiste en asignar a la información acústica una categoría conceptual, ya sea procedente de un fenómeno de la naturaleza, de un animal o de un ser humano.

Figuras 9 y 10. Ejemplo de la etiqueta “categorización” en inglés, en Strangers Things (Duffer et al., 2016), y de la misma etiqueta en español, en Élite (Salazar y de la Orden, 2018).
Por su parte, la “explicación” aclara el origen o la causa del sonido, como puede ser la acción de un personaje, la duración del mismo o cualidades del sonido relacionadas con el montaje audiovisual (voz en off). En las siguientes imágenes podemos observar dos ejemplos de esta etiqueta en la que se hace referencia al tema musical principal de la serie que se escucha de fondo (Figura 11) y a otra canción que suena en el producto audiovisual (Figura 12), aunque, en esta ocasión, se subtitula el título de la canción y el grupo musical que la canta.
Respecto a la técnica de traducción denominada “atribución” habría que indicar que se trata de la interpretación que se hace en el subtitulado sobre las causas, motivos y razones de algún suceso, ya sea por una cualidad de la voz, estado físico o atribuir algún adjetivo a un sonido. No obstante, tal como venimos apuntando desde el inicio de este apartado, en inglés se especifican muchos más sonidos que en español.

Figuras 11 y 12. Ejemplos de “explicación” en inglés, en Strangers Things (Duffer, et al., 2016), y en español, en Élite (Salazar y de la Orden, 2018).

Figuras 13 y 14. Ejemplos de “atribución” en inglés, en Strangers Things (Duffer et al., 2016), y en español, en La casa de papel (Pina, 2017).
Por último, nos detendremos en los datos arrojados a partir del uso de las técnicas de traducción intralingüística, que, al igual que en los subniveles anteriores, este tipo de traducción se vuelve a dividir en: “traducción literal”, “simplificación” (léxica y sintáctica) y “reducción” (condensación y eliminación).
Del gráfico siguiente se desprende la alta recurrencia de uso de la técnica “traducción literal” en el corpus. El hecho de que haya más en español solo se debe a la existencia de más diálogo que en la serie americana. Sin embargo, lo más significativo es que esta es la única técnica de traducción intralingüística utilizada en inglés. Creemos que este hecho se puede deber a dos motivos: por un lado, la lengua inglesa es más breve y concisa, al tratarse de una lengua sintética, que la lengua española, que es una lengua analítica, (Cantos y Sánchez, 2011) y, por otro lado, que los subtítulos en inglés son más fieles con el diálogo de los personajes que los subtítulos en español.

Gráfico 7. Resultados de las técnicas de traducción intralingüística.
Asimismo, es relevante señalar que el resto de las técnicas de traducción interlingüística sean tan poco utilizadas, sobre todo, en una modalidad de traducción centrada en las personas con diversidad funcional auditiva. A pesar de que numerosos expertos en técnicas de traducción multimedia y subtitulado (Gottlieb, 1992; Lomheim, 1995; Martí Ferriol, 2013) han hecho hincapié en la importancia de estas cuatro técnicas, así como en la necesidad de usarlas ante una modalidad de traducción que se ve limitada por motivos de espacio y de tiempo, observamos que, en la práctica real, según los datos de este corpus, esto no es así. Resultados muy parecidos se extraen del análisis del corpus de 50 películas con SpS en español realizado por Jiménez-Hurtado y Martínez-Martínez (2018) y del corpus compuesto por 30 filmes con SpS en español de Martínez-Martínez (2015). En ambos estudios la “simplificación léxica”, la “simplificación sintáctica”, la “condensación” y la “eliminación” obtuvieron un resultado inferior al 1 %.
Por lo tanto, parece legítimo pensar que en la actualidad se sigue la tendencia de traducir de forma literal y que, cualquier técnica de adaptación está perdiendo relevancia, al menos en el SpS.
5. Discusión de resultados
El análisis de las series anotadas nos ha permitido realizar una primera descripción de las prácticas actuales de SpS en series en streaming en inglés y español.
Como se ha explicado a lo largo de este trabajo, los resultados del análisis hacen referencia a dos aspectos fundamentales del proceso de traducción en esta modalidad de TEM en particular, el SpS. Por un lado, la selección del contenido acústico de la serie original y que es, a su vez, relevante para la comprensión del producto audiovisual por parte de los receptores intencionados y, por otro lado, las técnicas de traducción empleadas para trasladar dicha información al subtítulo en palabras.
De cada uno de los análisis del apartado anterior, se extraen resultados llamativos que resumimos a continuación.
En el SpS en inglés se proporciona mucha más información a los usuarios con diversidad funcional auditiva que en español. Este hecho se pone de manifiesto en las etiquetas “voz”, “alternantes” y “objeto”. Observamos, pues, que el SpS en inglés intenta proporcionar más información acústica para que el usuario final acceda más al conocimiento de la trama de la serie.
En español, sin embargo, nos hemos encontrado con numerosas omisiones de sonidos relevantes del texto origen. Por el contrario, en inglés no había ninguno. Esta es una de las mayores diferencias observadas entre ambas lenguas y, además, sorprendentemente, observamos que el SpS en inglés no omite ningún tipo de información relevante para el seguimiento de la trama de sus series y, por lo tanto, van por delante en acceso al conocimiento de la comunidad sorda.
En cuanto a las tres técnicas de traducción intersemiótica, categorización, atribución y explicación hemos podido corroborar los resultados de estudios de corpus anteriores que han utilizado el mismo sistema de anotado semántico (Martínez-Martínez, 2015; Jiménez-Hurtado y Martínez-Martínez, 2018). Estas tres técnicas son las utilizadas por antonomasia para traducir todos aquellos sonidos no verbales en palabras. Recordemos que su frecuencia por orden de uso ha sido categorización, explicación y atribución en el corpus. Así pues, podemos decir que nos encontramos con el primer parámetro común en ambas lenguas. No obstante, no podemos ignorar que el inglés era más rico que el español en el uso de estas etiquetas, a pesar de que contábamos con un número mayor de subtítulos de estudio en español que en inglés.
Si nos detenemos brevemente en la tipografía, hemos comprobado que en ambas lenguas se tiende a seguir las directrices propias de NetflIX, resultado que era esperable, y que los subtituladores profesionales para SpS no prestan mucha atención a las normas creadas por los organismos encargados en accesibilidad de cada país.
Para finalizar los resultados más significativos de este análisis, acabaremos exponiendo que el análisis arroja datos significativos sobre el uso predominante de la traducción literal frente al resto de técnicas de traducción intralingüística (simplificación léxica, simplificación sintáctica, condensación y eliminación).
6. Conclusiones
Esperamos que los datos arrojados a partir del análisis que hemos ofrecido de estos subtitulados para personas sordas en series en streaming en español y en inglés sirvan a múltiples objetivos de investigación. Es evidente que estos son unos primeros resultados comparando el SpS de un corpus de series en dos lenguas diferentes y que este corpus deberá ampliarse lógicamente para comprobar si estas tendencias se producen siempre así o, por el contrario, pueden verse modificadas. Asimismo, también se podrían llevar a cabo más estudios de este tipo en otras lenguas para observar si estos resultados son comunes en diferentes idiomas o si el SpS de cada país pone de manifiesto su propia idiosincrasia en los mismos. Igualmente consideramos relevante el estudio futuro de parámetros lingüísticos comunes de lenguaje simplificado en cada una de las lenguas de estudio.
También hemos avanzado nuevas técnicas de traducción utilizadas de forma sistemática en esta nueva modalidad, como son la categorización, la atribución y la explicación, que en estudios previos no habían sido consideradas. En este sentido, hemos perfilado que estas tres técnicas de traducción son más recurrentes en el SpS en inglés que en español.
Respecto al uso de las técnicas de traducción intralingüística de los productos analizados en el corpus, hemos llegado a la conclusión de que los SpS de las series en inglés ofrecen más información en su contenido, pues hacen un uso mayor de la traducción literal, y que, tal como apunta Martínez-Martínez (2022) “cualquier técnica de adaptación está perdiendo relevancia”. Así como de otras técnicas que permiten recoger en pantalla de forma casi completa los sonidos producidos en la banda sonora. Recordemos que el inglés es una lengua sintética que permite mayor número de caracteres por segundo en pantalla, lo cual favorece el uso de estas técnicas.
Por último, llegamos a la conclusión de que el corpus de etiquetas elaborado para el SpS en español puede aplicarse, sin duda, al SpS en inglés y seguramente a otras lenguas. Adaptando eso sí, algunas de las etiquetas a las particularidades de cada una de ellas.
Referencias
AENOR, norma UNE 153010 (2012): Subtitulado para personas sordas y personas con discapacidad auditiva. AENOR.
Álvarez de Morales Mercado, C. (2015). El subtitulado para personas sordas como discurso narratológico. Sendebar, 26, 57-81.
Baños Piñero, R., y Díaz Cintas J. (eds.) (2015). Audiovisual translation in a global context: Mapping an ever-changing landscape. Palgrave.
Bordwell, D., y Thompson, K. (2010). El arte cinematográfico: una introducción. Trad. Y. Fontal Rueda. Paidós.
Cabo Villarpriego, M. B. (2008). Estudio de estrategias de reducción en el subtitulado en español para sordos de Scoop, (Woody Allen, 2006) (Trabajo fin de máster). Universidad de Vigo.
Cantos, P., y Sánchez, A. (2011). El inglés y el español desde una perspectiva cuantitativa y distributiva: equivalencias y contrastes. Estudios ingleses de la Universidad Complutense, 19, 15-44.
Chion, M. (2008). La audiovisión: introducción a un análisis conjunto de la imagen y el sonido. Trad. A. López Ruiz. Paidós.
CNMC (2020). Panel de hogares. Comisión Nacional de los Mercados y la Competencia.
Cuéllar Lázaro, C. (2020). Untertitel für Gehörlose vs. subtitulado para sordos: el reto de hacer visible lo inaudible. MonTI: Monografías de traducción e interpretación, 12, 144-179. https://doi.org/10.6035/MonTI.2020.12.05
Davies, L. (2016). NetflIX and the Coalition for an Open Internet. En K. McDonald y D. Smith-Rowsey (Eds.). The NetflIX effect: Technology and entertainment in the 21st century (pp. 15-32). Bloomsbury.
DCMP (Described and Captioned Media Program). (2019). Acerca de DCMP. https://dcmp.org/about-dcmp
Duffer, M., Duffer, R., Levy, S., Stanton, A., y Thomas, R. (2016). Stranger Things (Serie de televisión). NetflIX.
Gónzalez López, A., Hernández Aguado, L., y Serrano Martínez, A. (2018). Subtitulado para sordos: análisis de corpus del sonido animal, alternante y narratológico de la serie Strangers Things (Trabajo fin de grado). Universidad de Granada.
Gorbman, C. (1987). Unheard Melodies. BFI.
Gottlieb, B. (1992). Subtitling: A new university discipline. En C. Dollerup y A. Loddegaard (Eds.). Teaching translation and interpreting: Training talent and experience (pp. 161-169). John Benjamins.
Jiménez Hurtado, C. (2010): Fundamentos teóricos del análisis de la AD. En C. Jiménez Hurtado, A. Rodríguez Domínguez y C. Seibel (Eds.). Un corpus de cine: teoría y práctica de la audiodescripción (pp. 13–56). Tragacanto.
Jiménez Hurtado, C., y Martínez Martínez, S. (2018). Concept selection and translation strategy: Subtitling for the deaf and hard-of-hearing. Linguistica Antverpiensia. New Series: Themes in Translation Studies, 14, 114-139.
Kalantzi, D. (2008). Subtitling for the deaf and hard of hearing: A corpus-based methodology for the analysis of subtitles with a focus on segmentation and deletion (Tesis doctoral. Universidad de Manchester.
Lindsey, C. (2016). Questioning NetflIX’s revolutionary impact: Changes in the business and consumption of television. En K. McDonald y D. Smith-Rowsey (Eds.), The NetflIX Effect. Technology and Entertainment in the 21st Century (pp. 173-184) Bloomsbury,.
Lomheim, S. (1995). L’écriture sur l’écran. Stratégies de sous-titrage à NRK: une étude de cas. FIT Newsletter-Nouvelles de la FIT, 14 (3-4), 288-293.
Martí Ferriol, J. L. (2013). El método de traducción: doblaje y subtitulación. Trama.
Martínez Martínez, S. (2022). Subtitulación para personas sordas. Enciclopedia de Traducción e Interpretación. https://www.aieti.eu/enti/subtitling_deaf_SPA/index.html
Martínez Martínez, S. (2015). El Subtitulado para Sordos: estudio de corpus sobre tipología de estrategias de traducción (Tesis doctoral). Universidad de Granada.
Martínez Martínez, S., Jiménez Hurtado, C., y Jung, L. (2019). Traducir el sonido para todos: nuevos retos del subtitulador para sordos. E-Aesla, 5, 411-422.
Neves, J. (2005). Audiovisual translation: Subtitling for the deaf and hard-of-hearing (Tesis doctoral). Universidad de Surrey, Roehampton.
Pérez Bowie, J. A. (2004). La adaptación cinematográfica a la luz de algunas aportaciones teóricas recientes. SIGNA, 13, 277-300.
Pessoa do Nascimiento, A. K. (2017) Translating sounds into words in subtitles for the deaf and hard of hearing: A corpus-based approach. Trabalhos em Linguística Aplicada, 56(2), 561-587.
Pina, Á. (2017). La casa de papel (Serie de televisión). NetflIX.
Poyatos, F. (1994a). La comunicación no verbal I. Cultura, lenguaje y comunicación. Istmo.
Poyatos, F. (1994b). La comunicación no verbal II. Paralenguaje, kinésica e interacción. Istmo.
Salazar, R., y de la Orden, D. (2018). Élite (Serie de televisión). NetflIX.
Valentini, C. (2006). A multimedia database for the training of audiovisual translators. The Journal of Specialised Translation, 6, 68-84.
Valentini, C. (2008). The Forlì corpus of screen translation: Exploring macrostructures. En D. Chiaro, C. Heiss y C. Bucaria (Eds.). Between text and image: Updating research in screen translation (pp. 37-50). John Benjamins.
Zárate, S. (2014). Subtitling for deaf children: Granting accessibility to audiovisual programmes in an educational way (Tesis doctoral). University College.
1 La norma UNE 153010 (2012), una reedición de la misma norma publicada en 2003 ha contribuido a la estandarización de la SpS en España, ya que pretende establecer unos requisitos mínimos de calidad y un grado razonable de homogeneidad en la SpS (AENOR, 2012). En cuanto a las directrices del DCMP (2019), estas han sido una referencia para el subtitulado para sordos de los medios de comunicación en Estados Unidos, tanto de entretenimiento como educativos, dirigidos a los consumidores de cualquier edad. Estas pautas se han a otros idiomas y, por tanto, son una referencia a nivel internacional.
2 Se escribirán en cursiva las estrategias de traducción que conforman el árbol de etiquetas en el cual nos hemos basado para este estudio de corpus creado por Martínez-Martínez (2015). Cabe señalar que solo aparecerán en cursiva las últimas etiquetas pertenecientes a cada una de las subdivisiones del mencionado árbol de etiquetas.
3 https://partnerhelp.netflIXstudios.com/hc/en-us/articles/217350977-English-Timed-Text-Style-Guide
4 https://partnerhelp.netflIXstudios.com/hc/en-us/articles/217349997-Castilian-Latin-American-Spanish-Timed-Text-Style-Guide