:: TRANS 26. MISCELÁNEA. Teoría y generalidades. Págs. 87-108 ::
Conectividad y cognición situada: análisis de verbalizaciones sobre el proceso traductor mediante elementos de la teoría fundamentada
-------------------------------------
Àngel Tortadès Guirao
Universidad de Vic-Universidad
Central de Cataluña
ORCID: 0000-0002-9660-9966
-------------------------------------
Se presenta la base teórica y un estudio exploratorio de registros conversacionales recogidos, gracias a la conectividad (potencial de interacción mediante la tecnología), en un marco de cognición situada durante la ejecución de tareas de traducción en un entorno didáctico en línea. El objetivo es el de hacer emerger patrones del proceso de traducción exclusivamente a partir de verbalizaciones. El análisis tiene lugar mediante los elementos básicos de la teoría fundamentada: diseño de investigación emergente, muestreo teórico, saturación teórica, etiquetado y categorización de los fenómenos por medio del método de comparación constante, tal como los conciben Strauss y Corbin (1998). El estudio, sobre diez verbalizaciones, constituye una parte del proyecto en el que se están analizando, mediante esta metodología, 200 conversaciones con la ayuda del programa para el análisis cualitativo de datos asistido por ordenador, Atlas-ti.
PALABRAS CLAVE: análisis del proceso traductor, análisis de verbalizaciones, conectividad, cognición situada, teoría fundamentada.
Connectivity and situated cognition: an analysis of verbalizations around the translation process using grounded theory elements
This article presents the theoretical basis and an exploratory study of exclusively conversational registers, collected thanks to connectivity (potential for interaction through technology), in a situated cognition framework during the execution of translation tasks in an online didactic environment. The aim is to bring out patterns of the translation process from verbalizations. The analysis takes place using the basic elements of the grounded theory: emergent research design, theoretical sampling, theoretical saturation, labelling and categorization of phenomena through the constant comparison method, as conceived by Strauss and Corbin (1998). The study, on ten verbalizations, is part of a project in which 200 conversations are being analyzed using this methodology with the help of the computer-assisted qualitative data analysis software, Atlas-ti.
key words: translation process research, analysis of verbalizations, connectivity, situated cognition, grounded theory.
-------------------------------------
recibido en junio de 2021 aceptado en abril de 2022
-------------------------------------
1. INTRODUCCIÓN
El presente estudio sigue la línea de investigación del análisis del proceso traductor que surgió a raíz de los análisis de verbalizaciones en el ámbito de la psicología, dentro del paradigma denominado teoría de la verbalización, que tuvo como referente Protocol Analysis, Verbal Reports as Data de 1984, de Ericson y Simon. Este paradigma se aplicaría posteriormente al análisis de protocolos en traducción o think aloud protocols, análisis de verbalizaciones sobre los procesos que va activando una persona a medida que traduce o, retrospectivamente, después de haber traducido, y se bifurca en una línea iniciada por House en 1988 y su propuesta de dialog protocols, en la que se analizan verbalizaciones registradas durante la ejecución colaborativa de una traducción. Para una visión general de los primeros estudios, ver el examen que hace Krings (2001).
A pesar del enorme avance en el conocimiento del proceso traductor que han aportado estos y los posteriores estudios sobre verbalizaciones, el paradigma entró, a grandes rasgos, en un período de subordinación, como herramienta de triangulación, en estudios multimetodológicos de registros de tecleado y de posicionamiento de la mirada y acabó en una fase de hibernación (Sun, 2011). Esta evolución se atribuye tanto a las objeciones que se han presentado sobre el método en cuanto a la validez y la fiabilidad de los datos (se ha discutido si estos pueden ser representativos de los procesos analizados o si el sistema de recogida puede alterar la realidad estudiada), como a las dificultades que entraña la organización de un estudio empírico con suficientes participantes. Por otro lado, también se han aducido posibles contradicciones entre epistemología y metodología de investigación, ya que, a medida que avanzan los conocimientos sobre el proceso traductor, los fenómenos aparecen cada vez más complejos y difíciles de someter a una lógica de control de variables. Para una visión de estas objeciones y de la situación actual del paradigma, ver el resumen que hace Jääskeläinen (2017).
A pesar de lo expuesto, este proyecto se propone continuar en la línea de análisis exclusivo de verbalizaciones, concretamente las colaborativas, debido a la aparición de un nuevo fenómeno en el ámbito de la traducción, el de la conectividad, tanto en el aprendizaje de la disciplina como en el desarrollo de la actividad profesional. Este fenómeno brinda la posibilidad de acercamiento a la realidad estudiada desde un nuevo paradigma de investigación, el de la cognición situada. La justificación de un estudio exploratorio exclusivamente a partir de verbalizaciones acerca del proceso traductor proviene pues de la posibilidad de articular los réditos de la conectividad con los principios de la cognición situada.
Conectividad
El concepto de conectividad proviene de la didáctica y debe entenderse con relación a la posibilidad que ofrecen los entornos virtuales de aprendizaje para generar y mantener redes de comunicación. En la definición de Keim y Cánovas (2020, p. 14-15), en mi traducción, se refiere a:
todo el potencial de interacción que, con el apoyo de la tecnología, tiene a su disposición una persona que forma parte de una comunidad de aprendizaje en un entorno de formación que puede ser el del grupo clase, pero que también puede ir más allá. Incluye las comunicaciones personales y con el grupo, así como las interacciones que inicia por sí mismo el alumno y que superan los límites del propio grupo, o las posibilidades de incorporar recursos de información, comunicación y reflexión que superan lo que la propia institución educativa ofrece y propone.
Keim y Cánovas destacan de esta perspectiva su vínculo con el constructivismo social de Vigotsky y, más recientemente, con las teorías del conectivismo propuesto por Siemens y la teoría de LaaN (Learning as a Network) de Chatti, Schroeder y Jarke.
La conectividad hace posible un aprendizaje colaborativo de la traducción a distancia, sin tener que renunciar a principios didácticos basados en el socioconstructivismo, principalmente porque las dinámicas de funcionamiento de estas redes permiten grados de interacción entre las personas participantes en el proceso de aprendizaje análogos a los que se producen en un entorno didáctico presencial convencional e incluso facilitan una interacción con elementos de fuera del aula. Esta relación entronca con el concepto promovido por Kiraly cuando menciona “the need for realistic, practice-oriented classroom activities” (Kiraly, 1995, p. 22) y con el de aprendizaje situado, entendido como un enfoque, en la formación de profesionales de traducción e interpretación, que depende del contexto y donde los estudiantes están expuestos a entornos y tareas de la vida real o simulados, dentro y fuera del aula (González Davies y Enríquez Raído, 2016).
Por otro lado, la conectividad aporta instrumentos que ofrecen la posibilidad de observar el proceso de traducción sin intervención, es decir, en el contexto natural en el que tiene lugar este proceso. Esto es así porque los entornos didácticos, si se han diseñado desde una perspectiva de aprendizaje colaborativo, pueden exigir a las personas participantes que ejecuten tareas interactivas de traducción escrita mediante interacción oral hasta alcanzar acuerdos de traducción y que estas interacciones queden registradas. De esta manera, como docente, se puede acceder, más adelante, tanto al resultado final de las tareas, al producto (una traducción terminada), como a la evolución de la ejecución de la tarea, al proceso (una discusión grabada) y, como analista, se puede acceder a los datos sin pedir a los participantes ningún esfuerzo adicional.
Cognición situada
El concepto de cognición situada proviene también de la psicología y entiende la cognición como “mental activity as dependent on the situation or context in which it occurs, whether that situation or context is relatively local (as in the case of embodiment) or relatively global (as in the case of embedding and extension)” (Robbins y Aydede, 2009, p. 3). El término, que concuerda con el de aprendizaje situado (Saivyer y Greeno, 2009, p. 348) mencionado más arriba, constituye un conjunto de líneas de estudio de los procesos cognitivos supeditados a los contextos donde estos procesos tienen lugar. Para poder estudiarlos surge la necesidad de un cambio de paradigma científico, salir del laboratorio y analizarlos en su contexto real. Así, en el campo de la traductología, Risku (2017, p. 292), afirma que:
understanding the underlying cognitive processes of translation might require research methods that go beyond verbally transparent and expressible translation strategies (which can be made visible, for instance, using think‐aloud protocols) and look “behind” the verbal processing that is directly observable and, thus, so prominently evident in translation.
Para hacerlo se apuesta por el uso de metodologías cualitativas aplicadas al análisis de todo el proceso traductor en su contexto auténtico (desde la emisión del encargo hasta la entrega del producto) en los entornos profesionales reales: “the need to study cognitive processes […] leads to process researchers increasingly drawing on ethnographic methods as established ways of studying the unique dynamics of individual activities in their authentic contexts” (Risku, 2017, p. 293).
Por otro lado, desde esta perspectiva de la cognición situada, la actividad en el aula ya no se ve como una fuente de recogida de datos para un estudio de laboratorio sino como un entorno natural donde ocurren procesos auténticos: “Although classroom and laboratory research have often been placed together, as belonging to one pole, and in opposition to field research, there are important differences between them. Classrooms are authentic settings where social and human-computer interactions take place in a natural way” (Muñoz y Martín de León, 2020, p. 61). Aquí también se ve la idoneidad de aplicar metodologías de investigación cualitativas:
This sets classroom research closer to ethnographic approaches than to experimental settings. On the other hand, classroom conditions are more flexible and can be more controlled than the circumstances of the workplace; for example, the same text can be translated by many translators, allowing comparisons that are not possible in the workplace. (Muñoz y Martín de León, 2020, p. 62)
Desde la perspectiva de este estudio, los principales réditos que aporta la intersección entre conectividad y cognición situada son que:
- Los datos se pueden obtener en un entorno natural sin intervenir. Esto es así porque las personas participantes desarrollan sus tareas como una más de tantas actividades que quedan registradas, dentro del transcurso normal de su actividad como aprendientes, con el conocimiento de que están siendo registradas. Por tanto, se puede considerar que no se está alterando el curso natural de las acciones. Esto permite poder observar de forma sistemática y directa tanto lo que se dice, como lo que se dice que se hace, como lo que se acaba haciendo en realidad, sin manipulaciones que puedan restar valor ecológico a los datos.
- Es posible acceder a multiplicidad de registros; no sólo a las grabaciones audiovisuales de las discusiones, también a los resultados de las tareas, a los registros de los tiempos invertidos para ejecutarlas, a la retroalimentación del profesorado, a tareas paralelas o a respuestas a preguntas adicionales que se pueden dirigir al alumnado. Todo queda recogido automáticamente en los instrumentos del aula virtual y todo es fácilmente accesible a posteriori sin necesidad de pedir esfuerzos adicionales a participantes si en el momento del diseño se ha tenido en cuenta un objetivo de investigación paralelo al objetivo de facilitar el aprendizaje.
- Es posible acceder a multiplicidad de perfiles de participante. Al tratarse de un grado en traducción en modalidad virtual, el espectro de personas participantes es mucho más amplio que en unos estudios presenciales. La comunidad está constituida por personas con características, antecedentes y lugares de residencia diversas. Además del modelo característico de participante de un grado presencial (persona joven, local, que proviene del bachillerato), en las aulas virtuales se encuentran personas adultas, personas no tituladas que ejercen como profesionales, personas nativas en una o en la otra lengua de trabajo o en las dos al mismo tiempo, personas residentes indistintamente en un país de su lengua de partida o de su lengua de llegada, personas no nativas en ninguna de las dos lenguas de trabajo, etc. Cada uno de estos perfiles aporta su idiosincrasia particular y esta variedad hace posible establecer comparaciones significativas entre las verbalizaciones.
Así pues, como en algunos de los estudios iniciales mencionados al principio, el estudio, de carácter exploratorio, se propone examinar procesos cognitivos a partir del análisis exclusivo de verbalizaciones colaborativas bajo la perspectiva de la cognición situada y en un entorno didáctico, no en un entorno profesional. Más allá de intentar entrar en la mente de una persona, se entra en el taller de traducción y se observa a las personas mientras están trabajando, interactuando y aprendiendo. El cambio de paradigma provoca la necesidad de ajustar la metodología de investigación sobre verbalizaciones a los principios epistemológicos de la cognición situada. En este sentido, la misma Risku (2017, p. 296) apunta la posibilidad de utilizar la teoría fundamentada y de organizar un estudio alrededor de tantos casos diferentes como sea posible con el objetivo de cubrir un amplio espectro. Jääskeläinen sugiere también que se podrían abordar las verbalizaciones en torno al proceso traductor como si se tratara de una narrativa: “Treating verbal reports as a kind of narrative rather than as objective accounts of processing steps might open up new kinds of avenues for using verbal reports”. (2017, p. 224). De este modo, con la convicción de poder hacer aportaciones en la investigación sobre el proceso traductor se procede a analizar las verbalizaciones mediante los procedimientos esenciales de la teoría fundamentada.
Teoría fundamentada
La teoría fundamentada (TF) nace con la publicación de The discovery of grounded theory: Strategies for qualitative research en 1967 como culminación de un estudio realizado sobre las interacciones entre el personal médico, pacientes y familiares en torno a los enfermos terminales en un hospital de San Francisco por Barney Glaser y Anselm Strauss. Proviene, por tanto, de las ciencias sociales y surge de la necesidad de analizar un fenómeno social (crear una teoría) a partir del análisis de grandes cantidades de datos (el fundamento para llegar a ella). Estos datos pueden ser de naturaleza diversa (entrevistas, diarios, cuestionarios, o también textos espontáneos como correspondencia o conversaciones).
La teoría fundamentada tiene una evolución compleja. Este estudio se ciñe a la actualización hecha por Strauss y Corbin en Basics of qualitative research. Techniques and procedures for developing grounded theory, de 1998 y a los patrones y denominadores comunes descritos por Charmaz (2014), complementados por la visión de manual de Penalva Verdú y Mateo Pérez (2006). En esta actualización, Strauss y Corbin dan cabida a la posibilidad de ceñirse a un método de inferencia no estrictamente inductivo, como proponía la teoría fundamentada en sus inicios.
En primer lugar, esta metodología se distingue por propiciar un carácter emergente al diseño de los estudios. El funcionamiento del sistema de análisis de la TF no es lineal, no se elabora un diseño previo, que es seguido por la recogida de datos, el etiquetado de los fenómenos y el posterior análisis y acaba, una vez cerradas las fases anteriores, con la reflexión y las conclusiones sobre todo el proceso, sino que se establece una relación de interdependencia entre todas las fases y un avanzar simultáneo en todas ellas. Esto significa que las decisiones sobre el diseño no se cierran al inicio del estudio, sino que pueden surgir nuevas o diferentes líneas que se añaden a las pensadas en las primeras fases de la investigación.
En palabras de Charmaz (2014), trabajar con esta metodología implica detenerse constantemente para escribir nuevas ideas, ya que algunas de las mejores de ellas pueden aparecer al final del proceso y pueden obligarnos a volver a los datos iniciales para obtener una visión más profunda de los fenómenos que hemos descubierto. A veces, también es posible darse cuenta de que el trabajo sugiere avanzar en más de una dirección analítica. Por lo tanto, cabe centrarse primero en ciertas ideas y terminar una obra o proyecto a partir de aquí, y luego volver a los datos y continuar con el análisis en otra área (Charmaz, 2014).
En relación con la recogida de datos y la selección de sujetos, la TF establece dos conceptos primordiales: el del muestreo teórico y el de la saturación teórica. A diferencia de un estudio empírico, en el que la selección de sujetos de estudio y el corpus de datos deben fijarse antes del análisis, dependiendo de las variables que se estudian para ratificar o no una hipótesis, en la teoría fundamentada la hipótesis es una respuesta provisional sobre las relaciones entre las categorías que surgen de los datos, relaciones que permiten, por un lado, fijar la categoría y, por otro, establecer la relación de la categoría con la teoría. Por lo tanto, no tiene sentido trabajar con una muestra establecida. En palabras de Penalva Verdú y Mateo Pérez (2006, p. 141) y mi traducción:
En esta fase, como en la inducción analítica, es posible verificar la hipótesis con la incorporación de nuevos casos o a través de una nueva lectura de los datos para determinar su validez. [...] Dado que se basa en un diseño emergente en el que la codificación, el análisis y la recopilación de datos se realizan a menudo simultáneamente, es posible recopilar más datos mediante nuevas aplicaciones de una o más técnicas. Para la comprobación de las hipótesis, se utiliza el muestreo teórico (se seleccionan nuevos casos a estudiar). La selección de estos se debe a su potencial para ayudar a refinar o ampliar los conceptos y teorías ya desarrollados.
Es decir, el muestreo teórico es el recurso que permite decidir, a medida que se desarrolla el análisis y surge la teoría, dónde se deben recopilar más datos para establecer las nuevas comparaciones necesarias para avanzar en el estudio.
De todas formas, debe haber un momento en que se detenga este muestreo teórico, ya no se realicen comparaciones y ya no sea necesario codificar. Este momento no ocurre arbitrariamente, sino que acontece por la consideración del analista de que su teoría ya está construida y que los nuevos datos que llegan no hacen más que ratificar lo que los datos anteriores ya han dicho. Cuando el analista comienza a percibir que no surgen nuevas variaciones entre los datos a través de comparaciones y que los nuevos fenómenos codificados explican relaciones ya desarrolladas y, por lo tanto, pertenecen a categorías ya existentes, en este momento se alcanza la saturación y se detiene el muestreo teórico.
La regla general al construir una teoría es reunir datos hasta que todas las categorías estén saturadas. Esto significa que a) no haya datos nuevos importantes que parezcan estar emergiendo en una categoría, b) la categoría esté bien desarrollada en términos de sus propiedades y dimensiones, demostrando variación, y c) las relaciones entre las categorías estén bien establecidas y validadas. La saturación teórica es de gran importancia. A menos que el investigador recopile datos hasta que todas las categorías estén saturadas, la teoría no se desarrollará de manera uniforme y carecerá de densidad y precisión. (Strauss y Corbin, 1998, p. 231-232)
En relación con los datos, la teoría fundamentada considera muy importante que estos sean ricos, detallados y anclados en su contexto. El analista debe sumergirse en ellos (en nuestro caso, verbalizaciones) y debe empezar a interpretar de manera analítica sus significados. Para ello, se debe proceder al etiquetado: la selección de fragmentos del discurso que son representativos de estos significados. Una vez explorados los primeros datos etiquetados, emergen conceptos más elaborados en forma de categorías iniciales (códigos). En este punto, la teoría fundamentada considera vital determinar para cada categoría o código: qué causas, consecuencias, tipos, procesos la han configurado. Es decir, explorar las propiedades y dimensiones de cada categoría. Los códigos deben cristalizar los significados y acciones que se encuentran en los datos. Como ayuda, se utilizan los memorandos, unas notas que ayudan, entre otras cosas, a fijar, modificar y describir los criterios de cada código. A lo largo de la investigación, este recurso se utiliza constantemente, ya que abre la posibilidad de establecer nuevas comparaciones, revisar códigos o incluso recopilar nuevos datos de otras maneras.
Para ello, se aplica el método de comparación constante (MCC), que hace referencia al ejercicio de cotejo, confrontación metódica entre los fenómenos observados y sus propiedades, entre diferentes tipos de sujetos, entre diferentes tipos de productos o diferentes tipos de registro. Mediante la aplicación de este método, van apareciendo transformaciones en el sistema de categorías: relaciones y conexiones entre ellas, fusiones e, incluso, la eliminación de algunas que al principio parecían relevantes. El resultado de esta fase es la transformación de las categorías iniciales en categorías más abstractas. Finalmente, el MCC es el que permite establecer comparaciones entre los distintos niveles de categorías, cosa que hace emerger fenómenos significativos en relación con el campo de estudio.
Los elementos que hemos explicado aquí nos ofrecen el soporte metodológico para poder trabajar directamente sobre el fundamento de un gran volumen de datos, desde la interpretación y bajo una concepción dinámica del proceso de investigación. Para evitar una interpretación sesgada, Risku (2017) menciona que el factor clave es asegurar un análisis detallado y sistemático sujeto a una lectura minuciosa y una explicación exhaustiva de cómo se ha llevado a cabo este análisis. Añade que los datos deben interpretarse y contextualizarse en varios pasos relacionados y que el análisis debe estar lo más cerca posible de los datos. Para hacer todo esto, recomienda el uso de software especializado.
CAQDAS
El término se corresponde con el acrónimo de Computer-Assisted Qualitative Data Analysis Software (Software de Ayuda al Análisis Cualitativo de Datos) y se refiere al conjunto de programas informáticos que surgen a mediados de los años 80 del siglo pasado, y en constante incremento en su uso hasta la actualidad, con el objetivo de facilitar el análisis de datos en estudios cualitativos, más allá de los recursos informáticos genéricos, como los procesadores de texto o las bases de datos, que se podían utilizar hasta determinado momento (Muñoz Justicia y Sahagún Padilla, 2017).
Como se ha dicho más arriba, en teoría fundamentada se trabaja con grandes volúmenes de datos para, en un proceso recursivo, conseguir una reducción que permita la búsqueda de significado en ellos. Para esto, el analista debe poder organizar de forma eficiente los ficheros donde descansan los datos, debe poder segmentar y codificar estos datos con facilidad y debe poder acceder en todo momento a ellos y al trabajo realizado sobe ellos, puesto que el proyecto de investigación va creciendo en todos sus flancos simultáneamente al ritmo que se van analizando datos. Los aspectos operativos, por tanto, son cruciales, porque en función de la forma en la que se concreten pueden favorecer o dificultar una aproximación sistemática, rigurosa, minuciosa y creativa a los datos (Muñoz Justicia y Sahagún Padilla, 2017).
El software para análisis cualitativo, sin automatizar procesos, ofrece un apoyo en la parte operativa del análisis sin el cual un estudio de estas características sería imposible. En este estudio se ha optado por el programa Atlas-ti, entre otros programas de análisis cualitativo, porque ofrece la posibilidad, directamente sobre el archivo de vídeo, de etiquetar fragmentos de conversación, codificarlos y establecer comparaciones constantes con otros fragmentos etiquetados y codificados también directamente sobre archivos de vídeo. Es decir, se puede trabajar directamente sobre la realidad (o una grabación de la realidad) y no sobre una transcripción de la realidad, cumpliendo con ello una máxima primordial de la teoría fundamentada y que recoge también Risku (2017) en su propuesta de aplicación de las teorías de la cognición situada al análisis del proceso traductor: trabajar en todo momento con la máxima proximidad a los datos.
Estudio
Los datos de este estudio se extraen a partir de la ejecución por parte de las personas participantes de una actividad de interacción oral en diversas asignaturas de traducción del alemán en un entorno de aprendizaje colaborativo en línea. La actividad (se puede consultar el enunciado en el anexo 1) se llama TransDialog y consiste en un videoencuentro en parejas o grupos pequeños en el que se debe acordar la traducción de un fragmento de texto. Los principales objetivos didácticos de la actividad son dos: en primer lugar, ofrecer a los estudiantes online un espacio virtual para la creación de conocimiento mediante la interacción colaborativa y, en segundo lugar, ofrecer al profesorado una herramienta para el seguimiento, a partir del vídeo, del proceso de traducción que cada alumno aplica con el fin de poder evaluar de manera formativa el proceso de aprendizaje de acuerdo con la perspectiva del andamiaje. Aparte de los objetivos didácticos, desde la perspectiva de la investigación el diseño de la actividad facilita la recogida de datos sin intervenir y da garantías sobre su autenticidad.
La actividad tiene lugar mediante una combinación de herramientas: videoencuentro, repositorio de vídeos y cuestionario Moodle. Los participantes, siguiendo las indicaciones del cuestionario, acuerdan y celebran el videoencuentro de forma autónoma sin la intervención del profesorado. En respuesta a las preguntas del cuestionario, los participantes deben escribir la traducción acordada y facilitar el enlace al fichero de la grabación del videoencuentro. La evaluación de la actividad, a partir de la visualización del vídeo, permite un seguimiento del proceso traductor.
La mayoría de participantes están familiarizados con la mecánica de la actividad TransDialog, puesto que constituye una variación de otra actividad, la actividad Dialog, para asignaturas de alemán como lengua extranjera en línea, que ya han cursado. Dialog es un instrumento de interacción oral para el aprendizaje a distancia del alemán que ofrece resultados (supervisables por el profesorado) de esta capacidad de interacción. En Dialog, el alumnado, en parejas o grupos pequeños, acuerda un videoencuentro y resuelve una actividad de producción oral que queda registrada. La actividad TransDialog es idéntica en términos de mecánica, pero, en lugar de perseguir un diálogo natural en lengua extranjera en línea, persigue la ejecución, entre dos personas o grupos de tres, de una tarea de traducción colaborativa, en un entorno de interacción oral natural, espontánea y desinhibida. Durante el curso 2016-17 se realizó una prueba piloto entre alumnado voluntario. El resultado de esta prueba, consistente en el análisis de seis grabaciones de una duración media de 90 minutos cada una y dos entrevistas post-facto, mostró el interés de la actividad TransDialog y la buena acogida por parte de las personas participantes y también dio lugar a algunas modificaciones. Desde entonces, la actividad se ha presentado como una actividad obligatoria en cada una de las tareas correspondientes a las unidades didácticas de las asignaturas de traducción del alemán del grado (un total de 8 unidades) en el formato que se detalla en el anexo 1.
De la ejecución de esta tarea se han recogido unas trescientas grabaciones, que se encuentran recopiladas y ordenadas en formato de archivo de vídeo. Doscientas de ellas, a partir de un muestreo teórico, son las escogidas para el análisis en la totalidad del proyecto, muchas de ellas se encuentran ya codificadas. Entre ellas se han escogido diez para este estudio exploratorio, que corresponden a las verbalizaciones durante la traducción de un mismo texto de partida (TP) por parte de veinte participantes. El contenido de los archivos ya es conocido por el analista, ya que las tareas han pasado por un proceso previo de revisión y de evaluación durante el periodo docente.
Segmentación y unidades de análisis
El mecanismo de análisis, como se ha dicho, parte del etiquetado de fenómenos observables en las conversaciones mediante un proceso de interpretación para poder establecer comparaciones más adelante. Por lo tanto, en primer lugar, se debe proceder a una segmentación del discurso. Es decir, se deben seleccionar fragmentos de la conversación para poder etiquetarlos con los nombres de los fenómenos que ocurren en cada fragmento seleccionado.
No se parte de un elenco de fenómenos definidos. Ya hemos explicado que la realidad de la conectividad permite acercarnos al proceso traductor desde una óptica situada y el interés de un estudio exploratorio puede radicar en observar qué fenómenos emergen desde esta óptica, no de contrastar si se cumplen unos fenómenos ya establecidos. Se procede pues a hacer emerger las categorías a medida que va evolucionando el análisis mediante una combinación de inferencia inductiva y deductiva.
El primer rompecabezas consiste en determinar qué fragmento de discurso es representativo de qué fenómenos. La dificultad de este paso radica en que cada participante verbaliza sus aportaciones, dudas, problemas, decisiones, consultas, etc. de forma idiosincrática y que para poder implementar el estudio basado en comparaciones es imprescindible, sin embargo, trabajar con unidades de análisis compatibles entre la totalidad de participantes. En este sentido, la capacidad de interpretación del analista es fundamental. Como afirma Pavlović en su estudio sobre verbalizaciones colaborativas: “various behaviors observed in the protocols generally are the expression of various processes occurring concomitantly. Because they are not ‘discrete’ operations, their coding may be difficult and, to some extent, depend on the subjective evaluation of the analyst” (Pavlović, 2007, p. 54).
En los estudios sobre el proceso traductor a partir de verbalizaciones se ha discutido sobre cómo proceder: a partir de problemas de traducción, de unidades de traducción, de unidades de cognición o de unidades de atención. Para tener una visión de estos conceptos y su evolución, consultar Alves y Valle (2009). Krings respalda el concepto de unidad de atención que aplica Jääskeläinen y que define “as those instances in the translation process in which the translator’s unmarked processing is interrupted by shifting the focus of attention onto particular task-relevant aspects” (Krings, 2001, p. 114).
De la aplicación de la metodología de comparación constante sobre los datos de este estudio, desde la perspectiva de la cognición situada, se concluye que una unidad de análisis que gire en torno a este concepto de “cambio de foco”, adaptado a la dinámica conversacional, puede ser operativa. Como consecuencia, en este estudio, se proponen, en primer lugar, unidades de análisis que se inician o terminan con un cambio de foco pactado, aunque sea tácitamente, entre participantes. Naturalmente, el proceso traductor no es lineal (ya lo dice Pavlović en la cita anterior) y en los datos de este estudio puede verse claramente como, cuando aparecen problemas de traducción, los focos de atención se solapan, redirigen y redimensionan. El registro de la conversación, sin embargo, sí que queda representado en el programa de análisis mediante un gráfico lineal. La habilidad como analista consiste en dimensionar (etiquetar) dentro de una cadena conversacional lineal una serie de fenómenos (categorías) que no ocurren de manera lineal. De ahí se deduce que la única posibilidad para poder llevar a cabo una segmentación de la cadena sea aplicar una vía interpretativa y, para evitar una visión sesgada, aplicar una metodología rigurosa y metódica mediante una mecánica estricta. Esto es lo que nos proporcionan el método de comparación constante de la teoría fundamentada y Atlas-ti.
La propuesta de este estudio, después de haber examinado la totalidad de los doscientos registros escogidos, es dividir estas unidades de atención en dos categorías: microunidades y macrounidades. De este modo, el total de cada flujo conversacional queda, en primer lugar, dividido en X macrounidades de atención, dentro de las cuales se encuentran diferentes microunidades.
Las macrounidades corresponden a los segmentos de conversación en los que las personas participantes verbalizan o dan muestra de que tienen su foco de atención centrado, de forma consensuada, en un bloque de trabajo y tienen in mente la totalidad de ese bloque mientras pueden ir emitiendo verbalizaciones sobre detalles de las piezas que juegan un papel en ese apartado. Características comunes de estas unidades, aparte de que son consensuadas, son que se abren y se cierran con un tipo de verbalizaciones explícitas sobre esta consensuación; que generalmente en ellas tienen lugar fenómenos relacionados con la totalidad del proceso traductor; que generalmente a lo largo de estas unidades las personas participantes toman como referencia, al principio, el texto de partida y, hacia el final, exclusivamente el texto de llegada; que generalmente se inicia el trabajo en el bloque con una lectura de la totalidad del fragmento correspondiente al TP; entre otras. La totalidad del segmento conversacional relativo a una de estas unidades se categoriza con códigos de nivel I, las categorías de nivel más abstracto. (Ver más adelante el apartado Codificación.)
Puesto que no se puede poner un ejemplo de transcurso de una unidad de este tipo en los datos recogidos, ya que corresponden a segmentos de conversación de diversos minutos de duración cuya transcripción ocuparía varias páginas, cabe decir que las conversaciones registradas para este estudio tienen lugar sobre una actividad de traducción de un texto de partida instructivo (ver anexo 2). Este texto presenta los contenidos distribuidos gráficamente en pasos. Los datos muestran que la mayoría de parejas trabajan consensuadamente a partir de estas macrounidades, que se pueden aislar con facilidad tanto visual como conceptualmente. Es decir, las parejas tienen el contenido de todo este apartado en la mente mientras van trabajando; han iniciado el trabajo con esta unidad con una serie de verbalizaciones explícitas al respecto y no abandonan el ámbito de esta unidad sin manifestarlo o proponerlo de manera explícita. En otras tipologías textuales que se están analizando para la totalidad del proyecto, las macrounidades de atención se establecen de maneras mucho más hetereogéneas.
Las microunidades de atención corresponden a segmentos de conversación en los que las personas participantes manifiestan, en un nivel generalmente individual, que tienen su foco de atención centrado en un fenómeno particular circunscrito dentro de una macrounidad o dan muestra de ello. Las personas participantes inician, abandonan o reemprenden el ámbito de una microunidad sin manifestarlo ni proponerlo de manera explícita. La totalidad del segmento conversacional relativo a una de estas microunidades se categoriza con códigos de nivel II, códigos con un grado de abstracción menor. A pesar de que los segmentos microetiquetados respondan a proposiciones, acciones o fenómenos de carácter más bien individual, cabe recordar que son segmentos extraídos de una conversación natural y, por ello, contienen necesariamente una proporción de realidad compartida entre participantes.
Codificación
La codificación, el segundo rompecabezas, se produce simultáneamente al proceso de etiquetado y con vistas al proceso de análisis y consiste en la asignación de códigos a los fragmentos etiquetados de la conversación en función de los fenómenos que en ese fragmento se pueden observar y que emergen de esta conversación y de la comparación constante con otras conversaciones. Los códigos pues, son categorías que emergen de los datos a través de la aplicación del método de comparación constante. Su papel será trascendental para poder establecer comparaciones posteriormente en el momento del análisis. Del mismo modo que con el etiquetado, al comparar constantemente las dimensiones y propiedades de cada categoría y en cada situación directamente sobre los datos, por medio del programa Atlas-ti, se alcanza a establecer unas demarcaciones estables para cada categoría. Solo mediante la ayuda del programa, que brinda, sobre todo, la oportunidad de navegar por todas las conversaciones y escuchar con un clic directamente cualquier segmento ya codificado, este proceso es posible.
Como se ha dicho al principio, la teoría fundamentada parte de un diseño emergente. De este modo, la delimitación de las unidades de atención (etiquetado) y sus tipologías se retroalimenta de la constitución del sistema de categorías y este sistema de categorías, de las primeras tentativas de análisis. Es decir, hasta que no se empiezan a vislumbrar los primeros resultados en la comparación entre diversas categorías en la fase de análisis, no se empieza a afianzar el árbol de códigos ni se pueden dar por definitivos los criterios de segmentación en el etiquetado.
Del mismo modo, el árbol de códigos no es definitivo hasta que no se llega a la saturación teórica y se da por terminado el estudio. En las primeras etapas del estudio los códigos eran numerosísimos y casi exclusivamente descriptivos. A medida que se ha ido avanzado, estos se han ido agrupando, se ha reducido su número y ha aumentado su nivel de abstracción.
Para facilitar el trabajo y poder ir asignando códigos a los segmentos etiquetados de manera sistemática es necesario agrupar los códigos en agrupaciones de códigos: (procedimientos, estrategias, problemas, argumentos, etc.). Hay códigos que pertenecen a más de una agrupación. Al mismo tiempo, todos los códigos se clasifican en niveles: nivel I (representados en mayúsculas) para las macrounidades y códigos de nivel II para las microunidades (en minúsculas).
En el anexo 3 puede consultarse un listado, sintético por razones de espacio, de los códigos relativos a los grupos “procedimientos”, “estrategias”, “interlocución”, “problemas”, “argumentos”, “situación” y “UNIDAD DE ANÁLISIS”, que han emergido del presente estudio. El formato es sintético en el sentido de que los códigos marcados con un 2 o un 3 indican que el código responde, en realidad, a dos o tres códigos diferentes, ya que hay códigos homónimos que se pueden aplicar a dos o tres áreas distintas. Por ejemplo, el primer elemento de la lista marcado con un tres corresponde en realidad a los tres códigos: “aportación de propuesta para la fase de comprensión”, “aportación de propuesta para la fase de fijación de la idea” y “aportación de propuesta para la fase de formulación de la idea en el TL”.
Para ayudar a comprender el procedimiento de etiquetado y codificación se muestra a continuación una captura de pantalla extraída directamente del programa sobre un ejemplo:
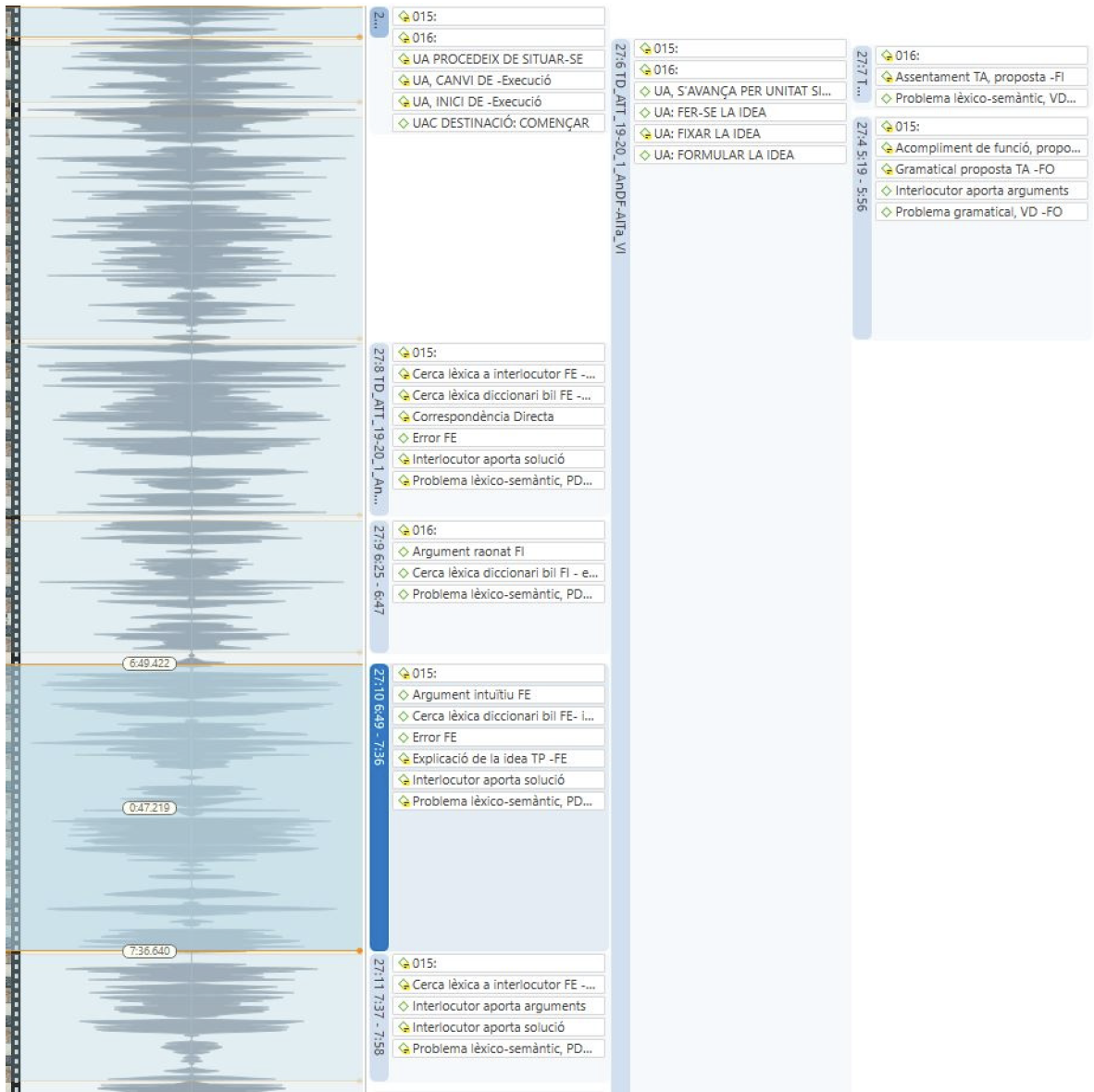
Fig 1. Ejemplo de etiquetado y codificación.
La captura de pantalla muestra una parte del tablero del programa Atlas-Ti durante el trabajo. La columna de la izquierda es una representación de un segmento de la cadena de sonido del fichero. No se ha capturado la columna que quedaría más a la izquierda (se asoma levemente), donde se visualizarían también las imágenes en cadena de las personas participantes. La captura corresponde a un fragmento de conversación de 3 minutos. En el programa, la parte anterior de la conversación quedaría por arriba y la posterior, por debajo.
El programa muestra el fichero sin solución de continuidad, por tanto, se puede colocar el cursor en cualquier parte de la conversación accionando la ruedecita del ratón. De este modo, pinchando en cualquier punto de la cadena de sonido, el programa permite visualizar y escuchar el vídeo en el punto seleccionado.
Las columnas de la derecha muestran las etiquetas que se han establecido para cada segmento de conversación considerado como unidad de atención. Por otro lado, dentro de las etiquetas se pueden ver los códigos de los fenómenos que se observan en esta unidad. En el programa, colocando el cursor en cualquier parte de la conversación mediante la ruedecita del ratón aparecen también las etiquetas y los códigos relativos al punto seleccionado.
De este modo, en la imagen, en la primera unidad (primera etiqueta que aparece por arriba al lado de la columna de sonido) pueden verse los códigos que la identifican como macrounidad de cambio de unidad. Esto quiere decir que ha sido codificada como segmento donde los participantes verbalizan consensuadamente que abandonan una unidad de atención e inician otra. Concretamente, los códigos corresponden a los participantes (015 y 016), y a lo que acontece en ese segmento: la decisión de un cambio de unidad de atención, la tipología de la unidad anterior y la tipología de la unidad que le sigue.
Lo que sucede a continuación se puede ver siguiendo en horizontal por arriba: Dos unidades más, que se producen simultáneamente, entran en escena. Una de ellas es de magnitud macro (en medio) y otra micro (a la derecha). La unidad de en medio ha sido codificada como macrounidad porque los participantes (015 y 016) han explicitado en la unidad anterior que se proponen trabajar sobre esta nueva unidad y porque no la dan por terminada consensuadamente hasta unos minutos más adelante, verbalizándolo también explícitamente. Simultáneamente, es decir, dentro del ámbito de la macrounidad mencionada, se pueden ver los códigos que muestran como la participante 016 hace unas verbalizaciones micro. A partir de aquí, y siguiendo hacia abajo, pueden verse las microunidades que los diferentes participantes van aportando a la conversación. Se ofrece a continuación la transcripción del audio de este mismo fragmento para facilitar la comprensión del proceso descrito hasta aquí. Recuérdese, sin embargo, que el proceso analítico transcurre directamente sobre los datos y no sobre una transcripción.
05:01 (015) Vale. Pues podemos… sí, el uno.
05:06 (015) Die Hefe
05:09 (016) Esto es diluir la levadura en agua
05:12 (015) Diluir la levadura en agua
05:16 (016) Bueno diluir o, no diluir, disolver, disolver.
05:19 (015) Disuelva será… o sea, usamos lo que aquí se usa ¿un poco como para las recetas?
05:21 (016) Como se usa más
05:26 (015) O sea, el, el, eh, como el impersonal, ¿no?
05:30 (016) Hm. Por eso. Disolver sería. ¿Como instrucciones? O prefieres…
05:37 (015) Sí, pero ¿disuelva o disolver? Ah, vale, por el infinitivo
05:40 (016) Por el infinitivo, o en imperativo. Como quier…, como prefieras
05:46 (015) Vale. No. Vale disolver, disolver la levadura en agua [teclea en voz alta]
06:00 (015) Mehl ¿Qué es? harina
06:00 (061) ¿Harina?
06:03 (015) sal, pimienta y mostaza. ¿No?
06:08 (016) No Muskat es…
06:10 (015) Muskat Ah! nuez moscada
06:12 (016) Eso, nuez moscada
06:17 (016) Sieben es que lo, tamizar, tamizarlo
06:19 (015) Schüssel es tamiz?
06:21 (016) No, Schüssel es un, una, una. ¿Un bol?
06:25 (015) Vale
06:27 (016) Pero sieben es de. Creo que es tamizar
06:31 (015) Vale
06:32 (016) Espérate, que lo busco para asegurarme, pero creo que es tamizar
06:36 (015) Colar, sí, colar, tamizar. Vale tamizar. O sea, eh, sieben. Eine Mulde hineindrücken. Molde. No. Una tolva. Mulde
06:54 (016) ¿Qué es una tolva? [risa]
07:02 (015) Una tolva es para meter polvos. Eine Mulde. Pero no sé si se dirá así. Vamos yo la conozco de, de, industrial. Pero, pero sí. Una tolva.
07:15 (016) Pues no sé qué es una tolva. Eh
07:21 (015) ¿No? Es como donde meten eso que es cónico, que es como un embudo, como un embudo. Por donde van cayendo los polvos
07:25 (016) Ah. OK
07:30 (015) Pero no sé cómo se dirá en cocina. Eindrücken ¿Y sabes lo que es hineindrücken?
07:32 (016) Drücken es como apretar y hinein es en ello O algo así. Es como apretarlo o algo así
07:45 (015) Ah vale. O sea, como… [lee el TP]
07:47 (016) Es como, como yo lo entiendo. Pero no lo sé, porque lo del Mulde no lo entiendo bien. Es como poner la harina, la harina, la sal, la pimienta y la nuez moscada en una, en un bol. O sea, tamizarlo, para tamizarlo en un bol
08:09 (015) Sí
08:14 (016) Y luego como ¿apretarlo?
08:19 (015) Sí. ¿Cómo se dice en…?
08:20 (016) ¡Ah! ¿Sabes lo que puede ser?
08:21 (016) ¡Ah!
08:22 (016) ¿Sabes lo que puede ser? A lo mejor es como hacerle un agujero en medio [gesticulaciones]
Así, en primer lugar, una brevísima verbalización: (“Vale. Pues podemos… sí, el uno”) constituye la primera macrounidad que describíamos arriba en la captura del registro de codificaciones. En ella se produce un acuerdo entre las personas participantes acerca del cambio de unidad de atención. La verbalización se refiere a que se disponen a abordar el apartado del texto de partida marcado con el número uno (ver el texto de partida en el anexo 1).
El resto de la conversación que se muestra en la transcripción constituye parte de la siguiente macrounidad de atención. Se ha etiquetado con los respectivos códigos de nivel I y dentro de ella se producen una serie de fenómenos relevantes. Cada uno de estos fenómenos ha sido etiquetado y codificado con los códigos correspondientes de nivel II: la participante 015 expresa una duda léxica; la participante 016 expresa una duda gramatical; la participante 016 introduce un elemento distorsionador al interpretar “Mulde” por “tolva”; la participante 016 verbaliza su problema para fijar la idea de lo que significa “eine Mulde hineindrücken”. Los códigos que coocurren con estos fenómenos corresponden a procedimientos, estrategias, tipología de argumentos, etc. que aplican las personas participantes ante el fenómeno concreto abordado en esa microunidad.
Resultados y conclusiones
Solamente a partir de la primera mecánica, la de la segmentación en unidades de atención mediante el método de comparación constante, ya se pueden observar fenómenos relevantes, como, por ejemplo, el papel que puede jugar el formato del texto de partida en la constitución de las macrounidades, la propia existencia de estas macrounidades, la evidencia de que cada una de las personas participantes trabaja con unidades de atención de distinto calibre simultáneamente, o que distintos participantes, en función de sus perfiles, trabajando con un mismo texto de partida, dimensionan sus unidades de atención de forma diferente o tienden a focalizar su atención en el texto de llegada con más o menos antelación. Se ratifican los resultados de estudios previos sobre verbalizaciones, por ejemplo, con referencia a la revisión que hace Jääskeläinen (2017), se evidencia una correspondencia entre fenómenos como el nivel de competencia de las personas participantes, la dificultad de la tarea o la tipología textual, por un lado y, por el otro, el tamaño de las unidades de atención, la linealidad del proceso traductor, la propensión a realizar variaciones léxicas o estructurales significativas entre TP y TL o el grado de consciencia metacognitiva. Desde esta perspectiva situada pueden apreciarse también fenómenos sorprendentes. Por ejemplo, que la tendencia a focalizar enseguida la atención, dentro de una macrounidad, hacia el texto de llegada es secundada no solamente por aquellos perfiles con buen nivel de competencia en la lengua de partida, sino justamente por el perfil opuesto. Es decir, que personas con un nivel bajo de competencia en la lengua de partida tienden a olvidarse rápidamente de acudir al texto de partida e intentan conseguir fijar la idea que expresa el texto de partida exclusivamente a partir de sus propias pretraducciones.
La segunda mecánica que propone la teoría fundamentada, el proceso de codificación sobre los segmentos etiquetados mediante la interpretación y la aplicación de la MCC, hace emerger también fenómenos relevantes, entre ellos la posibilidad y la conveniencia de clasificar la totalidad de verbalizaciones declarativas en torno a cuatro focos:
- Situarse: verbalizaciones colaborativas en torno a concretar acciones, distribuir roles, organizar elementos, etc., de manera que se pueda proceder a resolver la tarea de forma operativa.
- Hacerse la idea: verbalizaciones colaborativas dirigidas a la comprensión de lo que se expresa en la unidad de atención o más allá de la unidad de atención.
- Fijar la idea: verbalizaciones colaborativas dirigidas a describir, pormenorizar, diferenciar, situar, etc. lo que se expresa en la unidad de atención o más allá de ella.
- Formular la idea: verbalizaciones colaborativas dirigidas a la construcción del texto de llegada.
La posibilidad de observar conversaciones protagonizadas por participantes que interaccionan en lenguas diversas y en otras lenguas, aparte de las del par que entran en juego, ha sido decisiva para poder establecer y afianzar la diferenciación entre los últimos tres de estos cuatro focos.
La codificación también brinda la posibilidad de diferenciar entre modalidades de argumentación (categórica, intuitiva o razonada), entre tipologías de problemas (gramaticales, lexico-semánticos, ortotipográficos, de cohesión textual, coherencia…), entre verbalizaciones mediante las cuales se declara algo o bien a partir de las cuales se puede inferir que sucede algo, lo que abre la puerta a analizar fenómenos inconscientes. Todo ello a partir de la creación desde abajo, desde los datos, de un sistema de códigos coherente y sistemático.
Pero no es hasta la fase de análisis en la que se establecen comparaciones mediante las herramientas de Atlas-ti, principalmente la exploración de coocurrencias entre códigos, cuando afloran interrelaciones entre los códigos que pueden ser significativas. Así, por ejemplo, cotejando qué códigos coocurren con el código “encargo de traducción, desconsideración” se evidencia una constante de coocurrencia con el código “Verbalización denota problema gramatical en la formulación de la idea” y “Verbalización denota problema léxico-semántico en la formulación de la idea”. Es decir, de los datos se infiere que una falta de definición del encargo puede incidir en la aparición de problemas a la hora de fijar tanto la estructura gramatical como el léxico en el texto de llegada entre los participantes en el estudio. Un ejemplo de ello lo hemos podido ver en el fragmento de muestra: las participantes inician directamente su trabajo intentando fijar una formulación en la lengua de llegada, pero topan ya al principio con un dilema léxico (¿diluir o disolver?) y con un problema de adecuación de la estructura sintáctica a la función que debería ejercer el texto de llegada (¿infinitivo o imperativo?). No habían consensuado un encargo de traducción concreto antes de empezar el trabajo, como indicaba el enunciado de la tarea.
Más que unos resultados concluyentes, de este estudio exploratorio se esperaba poder ratificar la operatividad de entrar a analizar el proceso traductor a partir de un gran volumen de conversaciones sin intervenir, siguiendo la propuesta de Jääskeläinen (2017) de tratar las verbalizaciones como un tipo de narración en lugar de como relatos objetivos de los pasos del proceso traductor. Hemos visto, a partir del análisis de diez registros, que la combinación de la creatividad necesaria para la interpretación y la sistematicidad del método de comparación constante, como señalan Strauss y Corbin (1998), puede ayudar a este fin. Se espera que, con la consecución de la totalidad del proyecto, con el análisis sobre doscientas conversaciones, puedan aflorar nuevas evidencias que aporten luz al funcionamiento del proceso traductor. Más allá de este objetivo, cabe remarcar la utilidad de un estudio de estas características desde un punto de vista pedagógico, pues muestra una radiografía nítida de las acciones, resoluciones, estrategias y procedimientos que utiliza cada participante. En este sentido, en general, a partir de los datos, se puede ver que, por un lado, la fijación de un encargo de traducción resulta un instrumento de apoyo cognitivo en gran parte del proceso de traducción. Por otro lado, sin embargo, también se observa que la demanda de fijación de un encargo antes de una lectura en profundidad del TP (la tarea exige que se acuerde un encargo antes de empezar a traducir) puede ser contraproducente para algunos perfiles de estudiante, porque puede llevar a intentar que el texto de llegada cumpla una misión imposible. Pero, sobre todo, podemos ver que el principal problema general radica en una pobre “subcompetencia estratégica”, en la definición de PACTE (2003), la que, coordinando todas las estrategias, es responsable de encontrar una manera de resolver los problemas de manera eficiente. Así vemos que para la resolución de un problema sintáctico o cultural se utilizan herramientas para resolver problemas léxicos, que una pretraducción ejecutada con el objetivo de establecer la idea del texto de partida puede terminar interfiriendo con la producción de un texto de llegada apropiado o que algunas personas tratan de establecer una formulación de texto de llegada sin haber entendido el de partida, etc. Con esta información, respaldada por los registros, como docente se puede actuar, repensar los elementos que constituyen el modelo didáctico y dar una retroacción que posibilite un aprendizaje significativo.
Referencias
Alves, F., y Vale, D. C. (2009). Probing the unit of translation in time: Aspects of the design and development of a web application for storing, annotating, and querying translation process data. Across Languages and Cultures, 10(2), 251-273. https://doi.org/10.1556/Acr.10.2009.2.5
Charmaz, K. (2014). Constructing grounded theory: A practical guide through qualitative analysis. Sage.
González Davies, M., y Enríquez Raído, V. (2016). Situated learning in translator and interpreter training: bridging research and good practice. The Interpreter and Translator Trainer, 10(1), 1-11. http://dx.doi.org/10.1080/1750399X.2016.1154339
Jääskeläinen, R. (2017). Verbal reports. En J. W. Schwieter y A. Ferreira (Eds.), The handbook of translation and cognition (pp. 213-231) Wiley-Blackwell. https://doi.org/10.1002/9781119241485.ch12
Keim, L., y Cánovas, M. (2020). Ensenyar i aprendre des de la connectivitat. En L. Keim (Coord.), Connectivitat i dimensió social en la docència de la traducció (pp. 13-20). Eumo.
Kiraly, D. (1995). Pathways to Translation. Pedagogy and Process. Kent State University Press.
Krings, H. (2001). Repairing texts: Empirical investigations of machine translation post-editing processes, trad. Geoffrey S. Koby, Gregory M. Shreve, Katja Mischerikow, Sarah Litzer. The Kent State University Press.
Muñoz Martín, R., y Martín de León, C. (2020). Translation and Cognitive Science. En F. Alves y A. L. Jakobsen (Eds.), The Routledge handbook of translation and cognition (pp. 52-68). Routledge. https://doi.org/10.4324/9781315178127
Muñoz Justicia, J., y Sahagún Padilla, M.A. (2017). Hacer análisis cualitativo con Atlas-ti 7. Universitat Autònoma de Barcelona. http://manualatlas.psicologiasocial.eu/atlasti7.html
PACTE (2003). Building a translation competence model. En F. Alves (Ed.), Triangulating translation: Perspectives in process oriented research (pp. 43-66) Benjamins.
Pavlović, N. (2007). Directionality in collaborative translation processes. [Tesis doctoral, Universitat Rovira i Virgili]. http://hdl.handle.net/20.500.11797/TDX549
Penalva Verdú, C., y Mateo Pérez, M. A. (2006): Tècniques qualitatives d’investigació. Universitat d’Alacant, Secretariat de Promoció del Valencià.
Risku, H. (2017). Ethnographies of Translation and Situated Cognition. En J. W. Schwieter y A. Ferreira (Eds.), The handbook of translation and cognition (pp. 290-310). Wiley-Blackwell.
Robbins, P., y Aydede, M. (2009) A Short Primer on Situated Cognition. En P. Robbins y M. Aydede (Eds.), The Cambridge handbook of situated cognition (pp. 3-10). Cambridge University Press.
Strauss, A. y Corbin, J. (1998): Bases de la investigación cualitativa: técnicas y procedimientos para desarrollar la teoría fundamentada, trad. Eva Zimmerman. Universidad de Antioquía.
Saivyer, R. K., y Greeno, J. G. (2009) Situativity and learning. En P. Robbins y M. Aydede (Eds.), The Cambridge handbook of situated cognition (pp. 347-367). Cambridge University Press.
Sun, S. (2011). Think-aloud-based translation process research: Some methodological considerations. Meta, 56(4), 928-951. https://doi.org/10.7202/1011261ar
ANEXOS
ANEXO I. Página de entrada a la actividad didáctica en Moodle

ANEXO II. Fragmento del texto de partida a partir del cual se desarrolla la actividad en el estudio.
Eric Treuille, Ursula Ferrigno (2000): Brot: Rezepte aus aller Welt, München: Bassermann (116)

ANEXO III. Listado de los códigos que han emergido de las conversaciones del estudio
Informe de códigos (175)
Se trata de una lista compactada. El número inicial indica si el código se aplica a las verbalizaciones en un solo sentido, en dos, o en tres. Por lo tanto si en el estudio el título corresponde a un solo código, a dos o a tres. Por ejemplo el primer título marcado con un tres: “Aportación de propuesta”, en el estudio se corresponde a tres códigos en función de si la propuesta afecta a la fase de comprensión, a la de la fijación del la idea o a la formulación de la idea.
